En el competitivo mundo de la investigación de mercados y el desarrollo de productos, entender qué valoran realmente los clientes es la clave del éxito. No todas las características de un producto o servicio son iguales a los ojos del consumidor. Algunas son básicas y se dan por sentadas, mientras que otras tienen el poder de sorprender y deleitar. Para navegar esta complejidad, el Modelo Kano, desarrollado en los años 80 por el profesor Noriaki Kano y su equipo, emerge como una herramienta estratégica indispensable (Kano et al., 1984).
Este modelo nos permite clasificar las preferencias de los clientes en distintas categorías, ayudando a los equipos de producto a priorizar esfuerzos, invertir recursos de manera inteligente y, en última instancia, a crear productos que no solo satisfagan, sino que también enamoren a sus usuarios.
Los Fundamentos del Modelo Kano
El núcleo del modelo reside en que la relación entre el rendimiento de una característica y la satisfacción del cliente no siempre es lineal. Para descubrir esta relación, el Modelo Kano utiliza un cuestionario con una estructura única. Para cada característica a evaluar, se formulan dos preguntas clave (Berger et al., 1993):
Pregunta Funcional (Positiva): ¿Cómo se sentiría si el producto tuviera esta característica?
Pregunta Disfuncional (Negativa): ¿Cómo se sentiría si el producto no tuviera esta característica?
Las respuestas a ambas preguntas se eligen de una escala de cinco opciones:
Me gusta
Lo espero (o “Es algo que debe estar”)
Soy neutral
Puedo vivir con ello (o “No me molesta”)
Me disgusta
La combinación de las respuestas a este par de preguntas permite clasificar cada característica en una de las cinco categorías del modelo.
Las Cinco Categorías de Atributos del Cliente
El análisis Kano clasifica las características de un producto en cinco tipos, proporcionando una hoja de ruta clara para la toma de decisiones estratégicas en el desarrollo de productos (Matzler & Hinterhuber, 1998).
Atributos Básicos o Imprescindibles (Must-be): Son las características que los clientes dan por sentadas. Su presencia no genera una gran satisfacción, pero su ausencia provoca una profunda insatisfacción. Son los requisitos mínimos para competir en el mercado. Por ejemplo, que un coche nuevo tenga frenos es un atributo básico.
Atributos de Rendimiento o Unidimensionales (Performance): En este caso, la satisfacción del cliente es directamente proporcional al nivel de funcionalidad. A mayor rendimiento, mayor satisfacción, y viceversa. Un ejemplo claro es el consumo de combustible de un coche; cuanto menos consuma, más satisfecho estará el cliente.
Atributos Atractivos o de Entusiasmo (Attractive/Delighters): Estas son las características inesperadas que, si están presentes, generan sorpresa y deleite, aumentando significativamente la satisfacción. Su ausencia, sin embargo, no causa insatisfacción, ya que no eran esperadas. Son clave para la diferenciación. Por ejemplo, un sistema de aparcamiento totalmente autónomo en un coche de gama media.
Atributos Indiferentes (Indifferent): La presencia o ausencia de estas características no tiene un impacto real en la satisfacción del cliente. Las empresas deben evitar invertir recursos en atributos que caen en esta categoría. Por ejemplo, el material exacto de los tornillos del motor.
Atributos Inversos (Reverse): La presencia de estas características causa insatisfacción. A menudo, se trata de funciones excesivamente complejas o que simplifican en exceso una tarea que el usuario prefiere controlar. Identificarlas es crucial para no alienar a ciertos segmentos de clientes.
Aplicación Práctica: Análisis de Datos con R
Aunque no existe un paquete único y estandarizado para el análisis Kano en R, podemos realizar el análisis de manera muy eficiente utilizando el ecosistema tidyverse, especialmente los paquetes dplyr para la manipulación de datos y ggplot2 para la visualización.
Paso 1: Estructura de los Datos
Primero, necesitamos nuestros datos en un formato ordenado. Lo ideal es un dataframe con una fila por respuesta, por encuestado y por característica. Las columnas clave serían id_encuestado, caracteristica, respuesta_funcional y respuesta_disfuncional. Para facilitar el análisis, codificaremos las respuestas numéricamente:
1: Me gusta
2: Lo espero
3: Soy neutral
4: Puedo vivir con ello
5: Me disgusta
Paso 2: Creación de un Conjunto de Datos de Ejemplo
Imaginemos que hemos realizado una encuesta para una nueva aplicación de fitness y hemos evaluado tres nuevas características: “Seguimiento GPS en tiempo real”, “Planes de nutrición personalizados por IA” y “Gamificación con insignias y trofeos”.
Code
# Cargar las librerías necesariaslibrary(dplyr)library(ggplot2)library(tidyr)library(knitr)# Crear un dataframe de ejemplo con 100 encuestadosset.seed(42) # Para reproducibilidadn_respondents <-100caracteristicas <-c("Seguimiento GPS", "Nutrición con IA", "Gamificación")kano_data <-data.frame(id_encuestado =rep(1:n_respondents, each =length(caracteristicas)),caracteristica =rep(caracteristicas, times = n_respondents),respuesta_funcional =sample(1:5, size = n_respondents *length(caracteristicas), replace =TRUE, prob =c(0.4, 0.3, 0.15, 0.1, 0.05)),respuesta_disfuncional =sample(1:5, size = n_respondents *length(caracteristicas), replace =TRUE, prob =c(0.05, 0.1, 0.15, 0.3, 0.4)))# Ajustar las respuestas para simular un escenario realistakano_data <- kano_data %>%mutate(respuesta_funcional =case_when( caracteristica =="Seguimiento GPS"~sample(1:3, n(), replace =TRUE, prob =c(0.3, 0.6, 0.1)), caracteristica =="Nutrición con IA"~sample(1:3, n(), replace =TRUE, prob =c(0.7, 0.2, 0.1)),TRUE~ respuesta_funcional ),respuesta_disfuncional =case_when( caracteristica =="Seguimiento GPS"~sample(3:5, n(), replace =TRUE, prob =c(0.1, 0.3, 0.6)), caracteristica =="Nutrición con IA"~sample(2:4, n(), replace =TRUE, prob =c(0.1, 0.8, 0.1)),TRUE~ respuesta_disfuncional ) )kable(head(kano_data), caption ="Vista previa de los datos brutos del Modelo Kano.")
Vista previa de los datos brutos del Modelo Kano.
id_encuestado
caracteristica
respuesta_funcional
respuesta_disfuncional
1
Seguimiento GPS
2
5
1
Nutrición con IA
1
2
1
Gamificación
1
5
2
Seguimiento GPS
2
5
2
Nutrición con IA
1
3
2
Gamificación
2
2
Paso 3: Clasificación de las Respuestas
Ahora, creamos una nueva columna categoria_kano aplicando la tabla de evaluación estándar del Modelo Kano. Usamos case_when() para una implementación limpia y legible.
Paso 4: Agregación y Determinación de la Categoría Final
Agrupamos los datos por característica para contar cuántas veces fue clasificada en cada categoría. La categoría con la frecuencia más alta (la moda) será la designación final para esa característica.
Code
# Contar las clasificaciones por característicakano_summary <- kano_analysis %>%group_by(caracteristica, categoria_kano) %>%summarise(conteo =n(), .groups ='drop') %>%mutate(categoria_kano =factor(categoria_kano, levels =c("A", "P", "M", "I", "R", "Q"),labels =c("Atractivo", "Performance", "Básico", "Indiferente", "Inverso", "Cuestionable")) ) %>%# Asegurarse de que todas las combinaciones están presentes, rellenando con 0 si es necesariocomplete(caracteristica, categoria_kano, fill =list(conteo =0))# Determinar la categoría dominantekano_dominant <- kano_summary %>%group_by(caracteristica) %>%slice_max(order_by = conteo, n =1) %>%ungroup()# Mostrar la tabla resumenkable(pivot_wider(kano_summary, names_from = categoria_kano, values_from = conteo), caption ="Resumen de frecuencias por característica.")
Resumen de frecuencias por característica.
caracteristica
Atractivo
Performance
Básico
Indiferente
Inverso
Cuestionable
Gamificación
20
21
25
27
5
2
Nutrición con IA
73
0
0
27
0
0
Seguimiento GPS
12
18
36
34
0
0
Code
# Mostrar la tabla de categorías dominanteskable(kano_dominant, caption ="Categoría dominante para cada característica.")
Categoría dominante para cada característica.
caracteristica
categoria_kano
conteo
Gamificación
Indiferente
27
Nutrición con IA
Atractivo
73
Seguimiento GPS
Básico
36
Paso 5: Visualización de los Resultados
Una de las formas más efectivas de presentar los resultados es un gráfico de barras apiladas que muestre la distribución de las categorías para cada característica.
Code
ggplot(kano_summary, aes(x = conteo, y =reorder(caracteristica, conteo), fill = categoria_kano)) +geom_bar(stat ="identity", position ="fill") +geom_text(aes(label =ifelse(conteo >0, paste0(round((conteo/100)*100), "%"), "")), position =position_fill(vjust =0.5), size =3.5, colour ="white") +scale_x_continuous(labels = scales::percent) +scale_fill_manual(values =c("Atractivo"="#1f77b4", "Performance"="#2ca02c", "Básico"="#ff7f0e", "Indiferente"="#d62728", "Inverso"="#9467bd", "Cuestionable"="#8c564b")) +labs(title ="Análisis del Modelo Kano para Nuevas Funcionalidades de App Fitness",x ="Porcentaje de Respuestas",y ="Característica de la App",fill ="Categoría Kano" ) +theme_minimal() +theme(legend.position ="bottom")
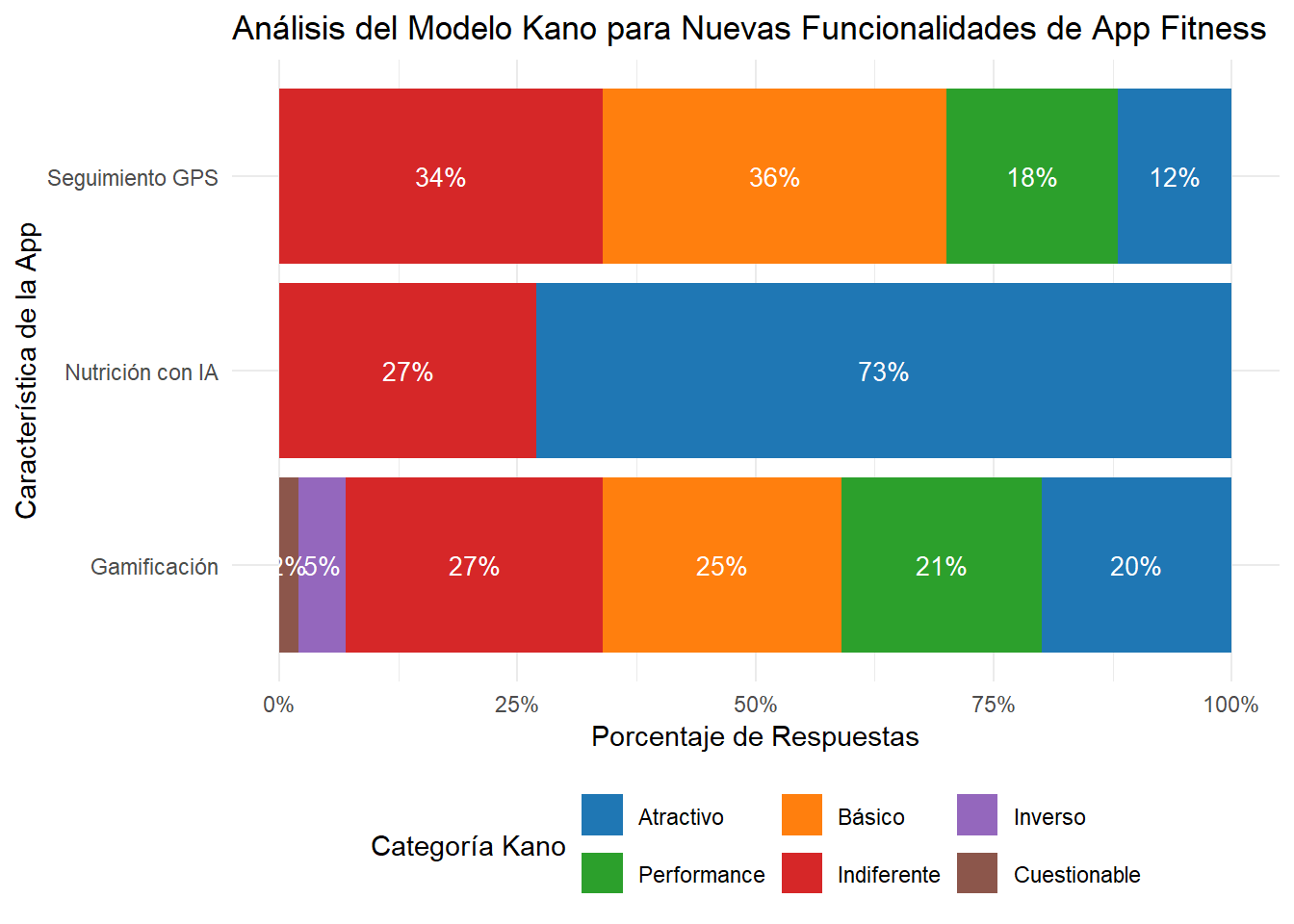
Distribución de la percepción del cliente por característica según el Modelo Kano.
Interpretación y Conclusiones
Al observar el gráfico y las tablas de resultados de nuestro ejemplo simulado, podemos extraer conclusiones estratégicas:
Seguimiento GPS: Se clasifica mayoritariamente como Básico (Must-be). Esto significa que los usuarios esperan esta funcionalidad en cualquier app de fitness seria. No tenerla causaría una gran insatisfacción. Decisión: Prioridad máxima. Debe ser implementado y funcionar a la perfección.
Nutrición con IA: En nuestro ejemplo, la categoría dominante es Atractivo (Delighter). No es algo que los usuarios esperen, pero su presencia genera un alto valor y diferenciación. Decisión: Gran oportunidad para destacar frente a la competencia. Si los recursos lo permiten, su desarrollo podría generar un gran impacto positivo en la adquisición y retención de usuarios.
Gamificación: Los resultados para esta característica son más mixtos, pero la categoría principal es Indiferente, seguida de cerca por Atractivo. Esto podría indicar que, si bien a un segmento de usuarios les encantaría, para la mayoría no es un factor decisivo. Decisión: Evaluar el coste-beneficio. Podría ser una característica a desarrollar en una fase posterior o a implementar de forma sencilla para no desviar recursos de los atributos básicos y de rendimiento.
En resumen, el Modelo Kano ofrece una “hoja de ruta” para el desarrollo de productos, permitiendo a las empresas enfocar sus recursos en las características que realmente importan a los clientes y que tendrán el mayor impacto en su satisfacción y lealtad.
Referencias
Berger, C., Blauth, R., Boger, D., & Bruce, C. (1993). Kano’s methods for understanding customer-defined quality. Center for Quality of Management Journal, 2(4), 3-35.
Kano, N., Seraku, N., Takahashi, F., & Tsuji, S. (1984). Attractive quality and must-be quality. Hinshitsu (Quality, The Journal of the Japanese Society for Quality Control), 14(2), 147–156.
Matzler, K., & Hinterhuber, H. H. (1998). How to make product development projects more successful by integrating Kano’s model of customer satisfaction into quality function deployment. Technovation, 18(1), 25-38. https://doi.org/10.1016/S0166-4972(97)00072-2