
Introducción
 La selección de un candidato a presidente del gobierno es un proceso crucial en cualquier sistema democrático. Los votantes se enfrentan a la tarea de evaluar y comparar a varios candidatos, cada uno de los cuales representa una amplia gama de cualidades y características. A medida que la política se vuelve cada vez más compleja y multidimensional, la necesidad de identificar al candidato más idóneo se convierte en un desafío que va más allá de la simple preferencia por un partido político. En este contexto, la técnica de Max-Diff emerge como una poderosa herramienta para evaluar y clasificar candidatos presidenciales en base a una serie de atributos específicos realizando sucesivas elecciones acerca de la mejor y la peor característica de entre subconjuntos de un conjunto de referencia (Louviere, Flynn, and Marley 2015). La técnica Max-Diff “es un enfoque de medición basado en elecciones que concilia la necesidad de parsimonia en las preguntas con la ventaja de las tareas de elección que obligan a los individuos a tomar decisiones (como en la vida real)” (Louviere et al. 2013); también conocida como análisis de máxima diferencia o como “best & worst analysis”, permite a los entrevistados clasificar estos atributos o ítemes en función de su importancia relativa. Este artículo se centra en la aplicación de la técnica Max-Diff, en el contexto de la elección de un candidato a presidente del gobierno, utilizando un conjunto de 13 atributos que caracterizan a estos líderes políticos. Al hacerlo, se revela una imagen más completa de las preferencias de los votantes y se identifican los aspectos que consideran más cruciales en la elección de la caracterización del objeto de estudio.
La selección de un candidato a presidente del gobierno es un proceso crucial en cualquier sistema democrático. Los votantes se enfrentan a la tarea de evaluar y comparar a varios candidatos, cada uno de los cuales representa una amplia gama de cualidades y características. A medida que la política se vuelve cada vez más compleja y multidimensional, la necesidad de identificar al candidato más idóneo se convierte en un desafío que va más allá de la simple preferencia por un partido político. En este contexto, la técnica de Max-Diff emerge como una poderosa herramienta para evaluar y clasificar candidatos presidenciales en base a una serie de atributos específicos realizando sucesivas elecciones acerca de la mejor y la peor característica de entre subconjuntos de un conjunto de referencia (Louviere, Flynn, and Marley 2015). La técnica Max-Diff “es un enfoque de medición basado en elecciones que concilia la necesidad de parsimonia en las preguntas con la ventaja de las tareas de elección que obligan a los individuos a tomar decisiones (como en la vida real)” (Louviere et al. 2013); también conocida como análisis de máxima diferencia o como “best & worst analysis”, permite a los entrevistados clasificar estos atributos o ítemes en función de su importancia relativa. Este artículo se centra en la aplicación de la técnica Max-Diff, en el contexto de la elección de un candidato a presidente del gobierno, utilizando un conjunto de 13 atributos que caracterizan a estos líderes políticos. Al hacerlo, se revela una imagen más completa de las preferencias de los votantes y se identifican los aspectos que consideran más cruciales en la elección de la caracterización del objeto de estudio.
A lo largo de este artículo, exploramos cómo se despliega el análisis Max-Diff en la evaluación de las características más valoradas en un candidato presidencial y cómo esta metodología puede aportar una comprensión más profunda de las prioridades de los votantes. Además, consideraremos la relevancia de este enfoque en el contexto de la toma de decisiones políticas y su potencial para influir en el proceso electoral. Con Max-Diff, se busca arrojar luz sobre las cualidades y características que los votantes consideran esenciales en un líder presidencial, lo que, a su vez, puede tener un impacto significativo en la formación de la opinión pública y en la toma de decisiones políticas informadas.
Por otro lado, no podemos obviar, la importancia del muestreo representativo en la extracción de conclusiones válidas y confiables a partir de un conjunto de datos. A menudo, los investigadores y encuestadores se enfrentan al desafío de trabajar con muestras que son una fracción mucho más pequeña que la población total que desean estudiar o entender. En tales casos, el muestreo representativo se convierte en una herramienta esencial, ya que permite hacer inferencias precisas y generalizables sobre la población en su conjunto. Un muestreo representativo implica la selección de una muestra que refleje fielmente la diversidad y las características de la población de interés. Esto significa que cada segmento, subgrupo o estrato dentro de la población debe estar representado en la muestra de manera proporcional. En otras palabras, se trata de capturar la esencia de la población en miniatura, de manera que las conclusiones basadas en la muestra sean aplicables a toda la población (Crick 2023).
Carga de los datos de encuestación
En este experimento se usa un denominado diseño balanceado incompleto, enfoque en el ámbito de la experimentación donde se planifican y realizan experimentos en los que no todas las combinaciones de factores y niveles están presentes en el diseño y que a diferencia de un diseño de experimento balanceado completo, donde todas las combinaciones posibles se prueban, se seleccionan cuidadosamente un subconjunto de combinaciones obteniendo un ahorro de recursos y una alta eficiencia estadística (White 2021). En nuestro caso se ha elegido un diseño con bswTools en el que sobre un set de 13 ítemes seleccionados cuidadosamente, se muestran 13 escenarios o tareas con 4 ítemes cada uno (Cochran and Cox 1957).
En este ejemplo, al encuestado se le presentaron trece tareas donde se le mostraban en cada escenario 4 ítemes, debiendo elegir entre los cuatro cuál consideraba que era la mejor y la peor característica de las cuatro mostradas. La pantalla se mostraba de este modo. Se redujo el efecto orden de los ítemes aleatorizando (por encuestado) su presentación en la pantalla.
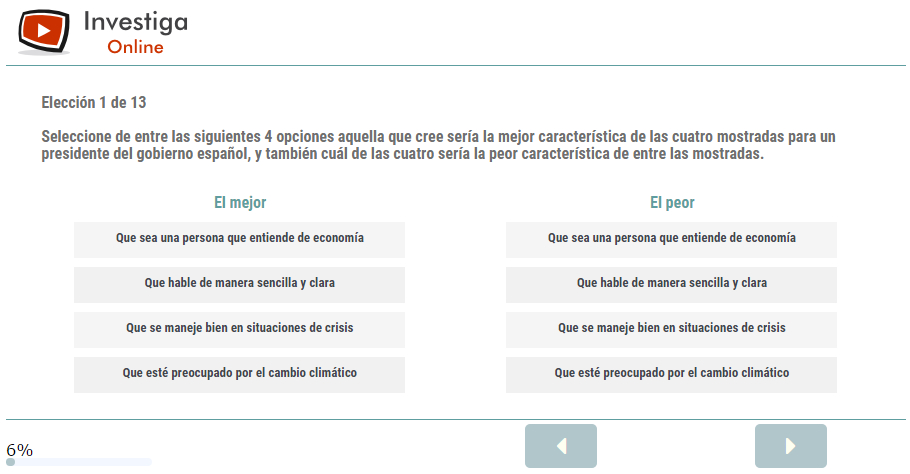
La primera tarea fue adecuar los datos originales de encuestación para que pueda realizarse el análisis multinomial. Como ejemplo Se muestra la estructura correspondiente a los cuatro primeros escenarios del individuo 1 encuestado.
En la siguiente tabla, las cuatro primeras filas responden al escenario 1, marcando con valor 1 la característica elegida como mejor, -1 para la peor y 0 las no contempladas. Nótese que las restantes 9 categorías no se listan en esta elección.
Cálculo de tabla best / worst
Siguiendo los pasos indicados en White (2021) usando bwsTools (White 2020) para obtener los resultados, el siguiente paso nos lleva a conocer qué items son los más y menos elegidos por los sujetos entrevistados. La siguiente tabla muestra el resultado directo de los trade-off realizados por cada sujeto en los distintos escenarios que se le han presentado.
Modelo multinomial, coeficientes
Nuestro siguiente paso es conocer el modelo multinomial (elección discreta) que se puede calcular con la estructura de datos. Un análisis multinomial es un tipo de análisis de regresión que se utiliza para modelar la relación entre una variable dependiente categórica con más de dos categorías y variables independientes. Los coeficientes en un modelo multinomial indican cómo las variables independientes influyen en la probabilidad de que un individuo o una observación pertenezca a una categoría en particular de la variable dependiente (Lipovetsky and Conklin 2014).
La interpretación de los coeficientes puede variar según el contexto del estudio. Es fundamental considerar el dominio específico y los conocimientos adicionales para comprender completamente el impacto de las variables independientes en la variable dependiente. La interpretación de los coeficientes en un análisis multinomial implica evaluar cómo las variables independientes afectan las probabilidades de pertenecer a una categoría particular de la variable dependiente en relación con la categoría de referencia. La dirección (positiva o negativa), el valor del coeficiente y su significado en el contexto son aspectos clave en esta interpretación.
Resultados agregados (ELO)
Calculamos a continuación los coeficientes diffscoring y ELO. En el contexto de un análisis multinomial, el coeficiente ELO utiliza para medir la preferencia de un individuo en una serie de opciones o categorías discretas. Por ejemplo, en esta encuesta ayuda a determinar las preferencias de características de un futuro presidente de gobierno. Para el cálculo de diffscoring, White (2021) indica que para cada encuestado se toma el número de veces que un elemento fue seleccionado como mejor y le resta el número de veces que fue seleccionado como peor. Esto significa que los valores potenciales varían de -r a +r, donde r se refiere a cuántas veces apareció cada elemento. Este valor se puede dividir por r, que devuelve una puntuación de diferencia normalizada para cada individuo.
Resultados individuales (e_bayes, elo, walk y pagerank)
A nivel individual se asigna una puntuación Elo a cada característica para cada individuo, lo que permitiría comparar y clasificar las preferencias de los individuos en función de sus puntuaciones Elo. El coeficiente Elo es una forma de asignar puntuaciones a individuos en función de sus preferencias o habilidades en categorías o opciones múltiples, y se basa en la idea de ajustar esas puntuaciones en función de las elecciones o resultados en comparación con otros individuos.
En el contexto del análisis MaxDiff y especialmente cuando usamos best and worst items (BWS), los coeficientes e_bayes, page y walk se refieren a estadísticas y medidas utilizadas para evaluar y analizar los resultados de un estudio de elección discreta. El análisis de best and worst items se utiliza para comprender las preferencias de los individuos al identificar los elementos que consideran los mejores y los peores en un conjunto de opciones (Hollis 2018).
A continuación, se explican brevemente los nuevos coeficientes añadidos:
Coeficiente e_bayes: Este coeficiente, a menudo llamado “e_Bayes,” se refiere al coeficiente de elección de Bayes. Es una medida que evalúa la probabilidad de que un elemento sea elegido como el mejor en una elección discreta, dadas las preferencias y elecciones observadas de los individuos. Un valor más alto de e_Bayes indica una mayor probabilidad de que un elemento sea considerado el mejor por la muestra. En lugar de utilizar el modelo de regresión logística multinomial bayesiano jerárquico, Lipovetsky y Conklin (2015) muestran una forma empírica de calcular analíticamente, obteniendo las probabilidades de elección y transformándolas para que estén en una escala de coeficientes de regresión lineal.
Coeficiente pagerank: El coeficiente Pagerank es otra medida utilizada en el análisis de best and worst items. Mide la probabilidad de que un elemento sea elegido como el mejor o el peor en una elección discreta, teniendo en cuenta las preferencias observadas. En otras palabras, evalúa la probabilidad de que un elemento sea considerado tanto el mejor como el peor por la muestra. Un valor más alto de PageRank indica una mayor probabilidad de que un elemento sea considerado extremadamente bueno o malo (White 2021).
Coeficiente walk: El coeficiente Walk se utiliza para evaluar la probabilidad de que un elemento sea elegido como el mejor en una elección discreta, teniendo en cuenta las preferencias observadas y el impacto de las preferencias en las elecciones subsecuentes. Este coeficiente toma en consideración la dinámica temporal de las elecciones y cómo las preferencias pueden influir en las elecciones futuras (White 2021).
Estos coeficientes son herramientas estadísticas que ayudan a analizar y comprender las preferencias de los individuos en un conjunto de opciones mediante el análisis de las elecciones discretas que hacen. Se utilizan para estimar las probabilidades de que un elemento sea considerado el mejor o el peor, lo que puede proporcionar información valiosa para la toma de decisiones y la comprensión de las preferencias del público objetivo.
Coherencia transversal de los coeficientes
Correlaciones de las mediciones …
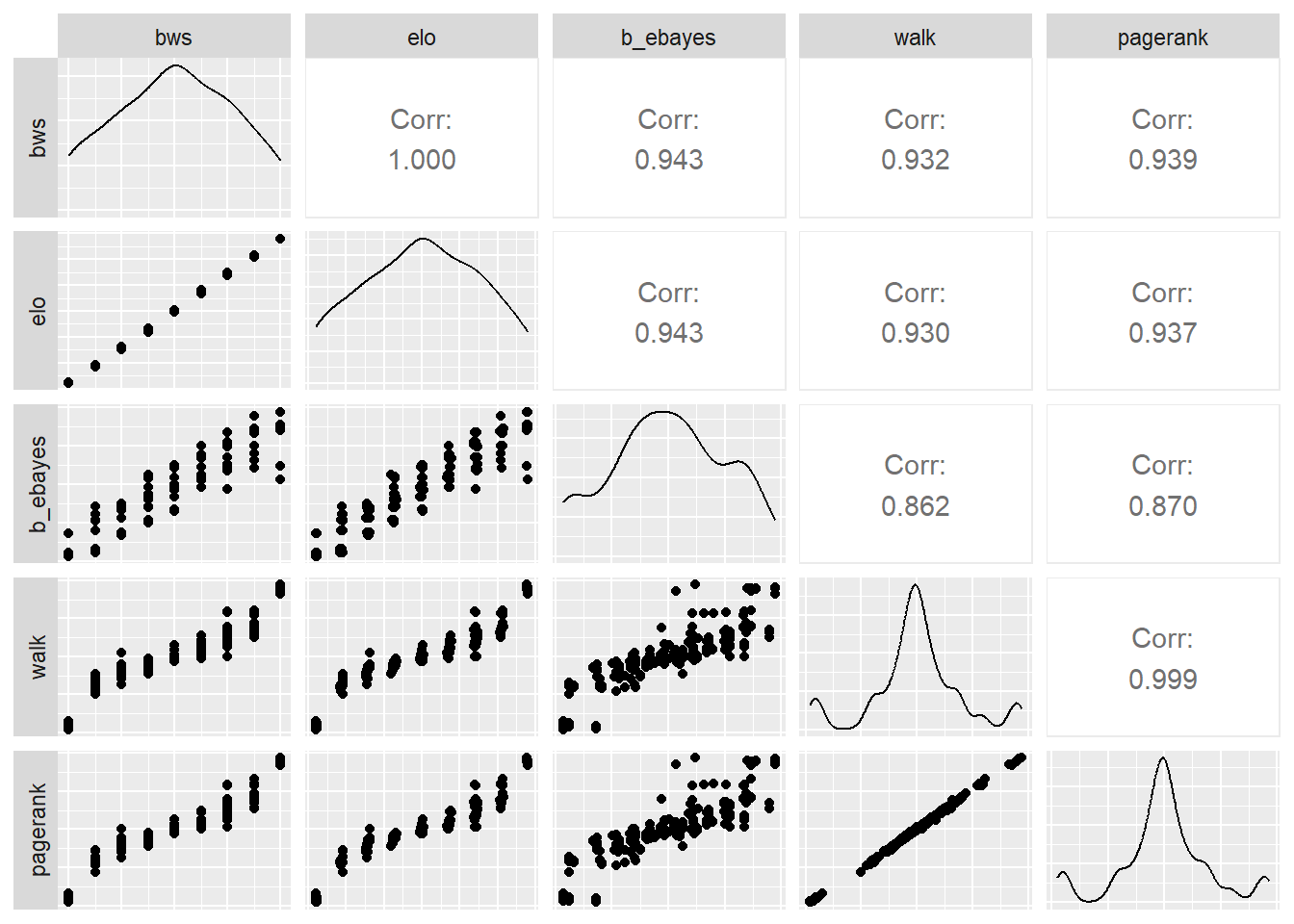
Por último y para confirmar el alineamiento de los índices calculados, se calcula la matriz de correlaciones para las puntuaciones individuales de los cuatro coeficientes calculados. La correlación es una herramienta estadística ampliamente utilizada para analizar la coherencia o similitud entre los resultados calculados utilizando diferentes fórmulas o métodos. Cuando se trabaja con índices o medidas, es común que haya varias formas de calcularlos, y la correlación puede ayudarte a determinar cuán consistentes o relacionados están esos cálculos. Una correlación cercana a 1 implica que los índices calculados con diferentes fórmulas están altamente relacionados en la misma dirección. Del mismo modo, una correlación cercana a -1 implica que los índices están altamente relacionados, pero en direcciones opuestas. Por último, una correlación cercana a 0 sugiere que no hay una relación lineal apreciable entre los índices (Siegel, Castellan, et al. 1972; Cohen 2013). En nuestro ejemplo la matriz de correlaciones muestra unos niveles muy altos de correlación positiva en todos los casos.
bws elo b_ebayes walk pagerank
bws 1.0000000 0.9998230 0.9428759 0.9316129 0.9391694
elo 0.9998230 1.0000000 0.9428317 0.9295508 0.9372890
b_ebayes 0.9428759 0.9428317 1.0000000 0.8618689 0.8699130
walk 0.9316129 0.9295508 0.8618689 1.0000000 0.9991782
pagerank 0.9391694 0.9372890 0.8699130 0.9991782 1.0000000Gráficos de correlación
Gráficamente …
References
Cochran, W., and G. M. Cox. 1957. Balanced and Partially Balanced Incomplete Block Designs (in Experimental Designs, 2nd Ed.). John Wiley & Sons, Inc.
Cohen, Jacob. 2013. Statistical Power Analysis for the Behavioral Sciences. Academic press.
Crick, J. 2023. “Analyzing Survey Data in Marketing Research: A Guide for Academics and Postgraduate Students.” Journal of Strategic Marketing, 1–13.
Hollis, G. 2018. “Scoring Best-Worst Data in Unbalanced Many-Item Designs, with Applications to Crowdsourcing Semantic Judgments.” Behavior Research Methods 50 (2): 711–29. https://doi.org/10.3758/s13428-017-0898-2.
Lipovetsky, S., and M. Conklin. 2014. “Best-Worst Scaling in Analytical Closed-Form Solution.” Journal of Choice Modelling 10 (March): 60–68. https://doi.org/10.1016/j.jocm.2014.02.001.
———. 2015. “MaxDiff Priority Estimations with and Without HB-MNL.” Advances in Adaptive Data Analysis 7 (01n02): 1550002.
Louviere, J., T. N. Flynn, and A. Marley. 2015. Best-Worst Scaling: Theory, Methods and Applications. Cambridge University Press.
Louviere, J., I. Lings, T. Islam, S. Gudergan, and T. Flynn. 2013. “An Introduction to the Application of (Case 1) Best–Worst Scaling in Marketing Research.” International Journal of Research in Marketing 30 (3): 292–303. https://doi.org/10.1016/j.ijresmar.2012.10.002.
Siegel, S., N. J. Castellan, et al. 1972. Estadı́stica No Paramétrica Aplicada a Las Ciencias de La Conducta. Vol. 4. Trillas Distrito Federal, México.
White, M. 2020. bwsTools: Tools for Case 1 Best-Worst Scaling (MaxDiff) Designs. https://CRAN.R-project.org/package=bwsTools.
———. 2021. “bwsTools: An R Package for Case 1 Best-Worst Scaling.” Journal of Choice Modelling 39 (June): 100289. https://doi.org/10.1016/j.jocm.2021.100289.