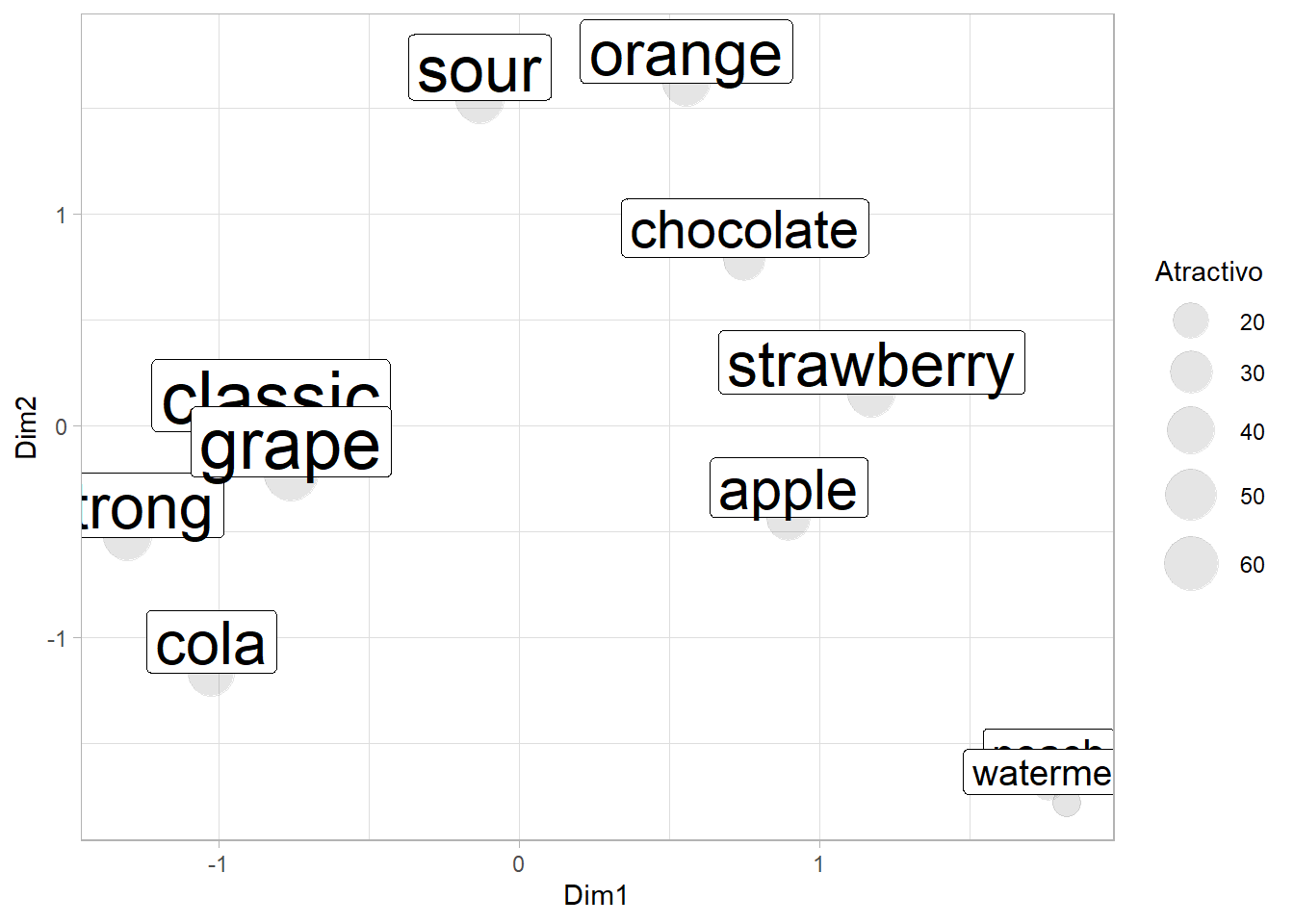Hacía tiempo que no escuchaba hablar de él, pero ha vuelto a mi. TURF es un acrónimo anglosajón para Total Unduplicated Reach and Frequency. Este análisis es ampliamente utilizado en el mundo del marketing desde hace años, ya que nos da pistas y respuestas a dos situaciones muy habituales en el análisis de cartera de productos, aunque su uso se puede extender a otros ámbitos muy diferentes:
Por un lado, cuando una compañía dispone de una cartera de productos que quiere extender, pero teniendo las limitaciones de producción o presupuestarias que le impiden desarrollar sólo algunos de ellos, TURF les ayudará a elegir cuáles son los más apropiados.
otro ámbito de trabajo podría ser en qué medios de comunicación debe enfocarse una empresa al distribuir contenido; ¿en qué redes publicitarias y medios debería centrarse?
otro ámbito podría ser el político; sabiendo que en un discurso de un líder político solo nos podemos centrar en 4 o 5 temas fundamentales de los 10 que podemos abordar, ¿con qué temas alcanzaríamos más a nuestro target?
Este documento intenta exponer un caso basado en una base de datos obtenida del sitio de displayR y cubre todo, desde la preparación de datos hasta la visualización e informes de datos.
Los paquetes que vamos a utilizar son básicos para cualquier analista de datos trabajando con R:
readxl (carga de excel)
expss (tablas)
ca (análisis de correspondencias)
psych (análisis multivariante clásico)
ggplot2 (gráficos adaptables)
turfR (análisis TURF)
Descripción de la base de datos
Un estudio TURF requiere un conjunto de datos que consiste en:
Datos de al menos 100 personas, e idealmente muchas más
Para cada persona, las mediciones del atractivo de tres o más alternativas diferentes, que generalmente son productos o contenido. Estas mediciones pueden ser de escalas de calificación, datos históricos de compra, MaxDiff o utilidades conjuntas o predicciones de preferencias.
En nuestro caso, la base de datos enlace es una hoja de cálculo EXCEL con 712 registros (713 filas) y dispone de 15 columnas (primera fila), donde la primera columna es el id (identificador) del individuo la segunda el peso del individuo en la muestra (representatividad de la población) y el resto son las diferentes alternativas de producto en la cartera de producto de una empresa fabricante de goma de mascar, las 11 siguientes son las diferentes alternativas testadas en un hall test y por último edad y género del individuo. En nuestro caso el peso es en todos los casos igual a 1, de forma que ningún individuo pondera más que otro. No ha existido equilibraje de la muestra.
Un fabricante de chicles estaba vendiendo dos sabores de chicle, Classic y Cola, y decide extender la gama a cuatro sabores. Se realizó una encuesta a 712 padres, donde los padres les preguntaron a sus hijos cuál de los 11 sabores les gustaba. Los porcentajes que gustan de cada uno de los sabores se muestran a la derecha. Esto se conoce como alcance total no duplicado, que es un término de la planificación de medios, donde el enfoque se centraba en comprender los medios de comunicación (por ejemplo, qué combinación de cuatro revistas llegaría al mayor número de personas). Por lo general, se llama simplemente “alcance” (reach) para abreviar.
Las diferentes alternativas son:
classic
strong
grape
sour
orange
strawberry
cola
apple
chocolate
peach
watermelon
La preparación de datos consiste en convertir cada medida a una variable binaria, donde un 1 indica que a la persona le gusta lo que se está midiendo, un 0 indica lo contrario. Las columnas de las alternativas podrás por tanto ver que son binarias. Aquí te mostramos las 5 primeras observaciones de nuestra tabla de datos.
Los datos pueden ser medidos de diferentes formas (que luego se binarizan).
Escalas de calificación como por ejemplo, la intención de compra, se usan comúnmente en los estudios TURF. Para usar estos datos, primero es necesario convertir los datos en formato binario. Por ejemplo, asignar un 1 a todos los que han dicho “Definitivamente comprará” y “Probablemente comprará” y un 0 a todos los demás.
Datos MaxDiff que también se pueden usar en TURF, pero es necesario convertirlos primero a un formato binario. Hay varias formas de hacerlo:
Alternativas mejor clasificadas. A las alternativas mejor clasificadas para cada observación se les asigna un valor de 1 y las demás un valor de 0.
Selección basada en el umbral. Se especifica algún umbral (por ejemplo, servicios públicos por encima del promedio del encuestado), y las alternativas con un servicio público por encima de este valor tienen asignado un valor de 1 y otras un valor de 0.
Las reglas basadas en probabilidad, como las alternativas con una probabilidad superior al 10% tienen un valor de 1. Este último enfoque no es aconsejable, ya que los factores de escala significan que el factor determinante clave de las probabilidades es la cantidad de ruido en sus datos, por lo que si Si utiliza un enfoque como éste, terminará sesgando el MaxDiff hacia las personas que fueron indecisas e inconsistentes en su MaxDiff.
Los datos de conjoint analysis también se pueden usar de la misma manera que con MaxDiff, utilizando niveles de un atributo o productos simulados.
En nuestro caso vamos a realizar un análisis TURF para portfolio de productos que tenga de 4 alternativas. De este modo, veremos que conceptos de resultado se manejan en un TURF. Solo mostraremos las cinco alternativas mejores en base a los resultados.
data <-as.data.frame(data[,1:13])suppressMessages(turfprods <-turf(data, 11, 4))
4 of 11: 0.3756049 sec
total time elapsed: 0.3769619 sec
La forma en que funciona un estudio TURF básico es que examina el alcance de todas las carteras (combos = combinaciones) posibles de los cuatro sabores (alternativas) y calcula el alcance de cada uno de ellos. Los resultados se muestran a la derecha. Cada combinación está numerada para su identificación, y la tabla se muestra ordenada por el alcance (reach).
La combinación ganadora es classic + grape + sour + strawberry con un reach de 95.1%, algo mayor que el 94.4% de la cartera número dos, que tiene cola apareciendo en lugar de grape. Este 0.7% no es una gran diferencia, representando solo 5 de las 712 personas.
Algunas personas se decepcionan cuando TURF no elige un ganador claro. Sin embargo, es una noticia extremadamente buena, ya que significa que hay mucha flexibilidad para tener en cuenta otros factores (es decir, la investigación no está cerrando oportunidades).
Por otro lado tenemos la columna con el dato de frecuencia de cada combinación. La frecuencia de 2,08 nos dice que si ofrecemos estos cuatro sabores, el número total de menciones en nuestra muestra a esas cuatro alternativas es 2,08 veces mayor que la muestra.
También, ten en cuenta que si bien las dos primeras carteras están muy cerca en términos de alcance, hay una gran diferencia en términos de frecuencia, con la segunda alternativa con una frecuencia 11% menor. Mirar la frecuencia hace que la primera, tercera y quinta combinación parezcan las más destacadas.
Tabla de duplicaciones
El siguiente paso en el análisis es la tabla de duplicaciones. dado que el conjunto de respuestas puede tratarse como una variable de tipo múltiple (binarizada) el cruce la variable por sí misma nos revelará todas las duplicaciones realizadas en la muestra entre todos los sabores.
Por otro lado, la diagonal principal de la tabla de duplicaciones, que como puede verse en la tabla inferior es el marginal de la variable múltiple (binarizada) muestra el alcance sobre la muestra de cada sabor por separado.
tab2 <- data %>%tab_cells(mdset(classic %to% watermelon)) %>%tab_stat_tpct(total_row_position='none') %>%tab_pivot()tab2
#Total
classic
65.9
strong
41.7
grape
60.1
sour
43.3
orange
39.9
strawberry
39.0
cola
37.5
apple
31.5
chocolate
26.7
peach
16.6
watermelon
16.3
Análisis de correspondencias de la tabla de duplicaciones
La tabla de duplicaciones muestra qué porcentaje de la muestra intersecciona o combina entre sí. Sin embargo, esta tabla de contingencia, puede analizarse con un análisis de correspondencias. Este análisis, revela la relaciones que existen entre los distintos sabores que se presentan. El gráfico resultante se muestra a continuación, con cada burbuja indicando el atractivo de cada alternativa. Cuanto más separadas están las burbujas, menos son sustitutos. Idealmente, queremos elegir alternativas que estén muy separadas. Esto plantea problemas con nuestra cartera actual preferida de Classic + Grape + Strawberry + Cola, con Classic y Grape superpuestos, y Cola está en la misma vecindad.
#analisis de correspondencias (ca)caanalysis <-ca(tab1)options(width=9999)caanalysis
El análisis de correspondencias proporciona un gran resumen de los datos. Pero, lo obliga a una trama bidimensional, lo que significa que ofrece algo de información pero no de modo completo. Con un mayor número de alternativas, esto se convierte en un problema grave. De este modo, podemos obtener una comprensión con un enfoque más amplio de la sustitución mediante el uso de análisis de componentes principales.
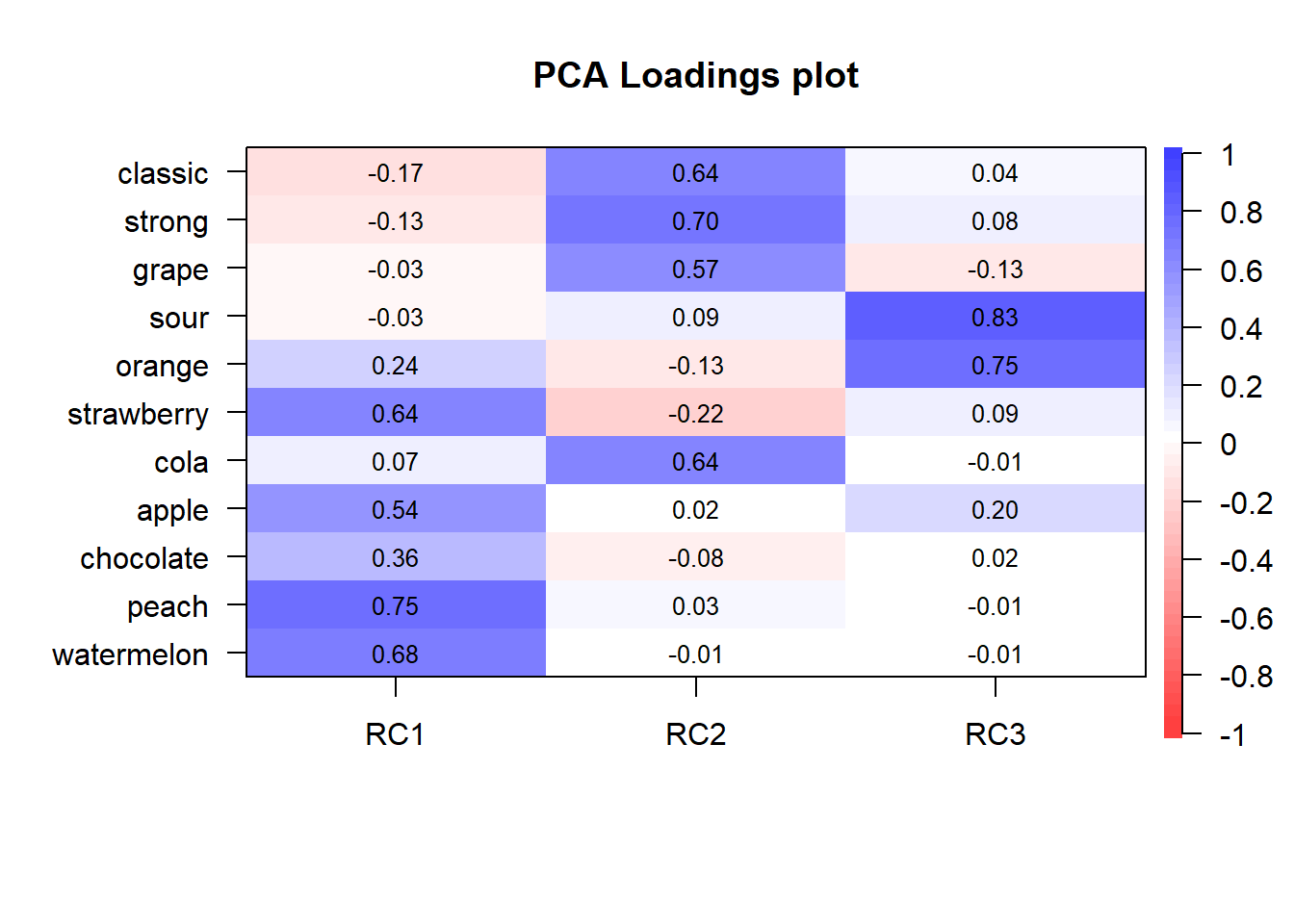
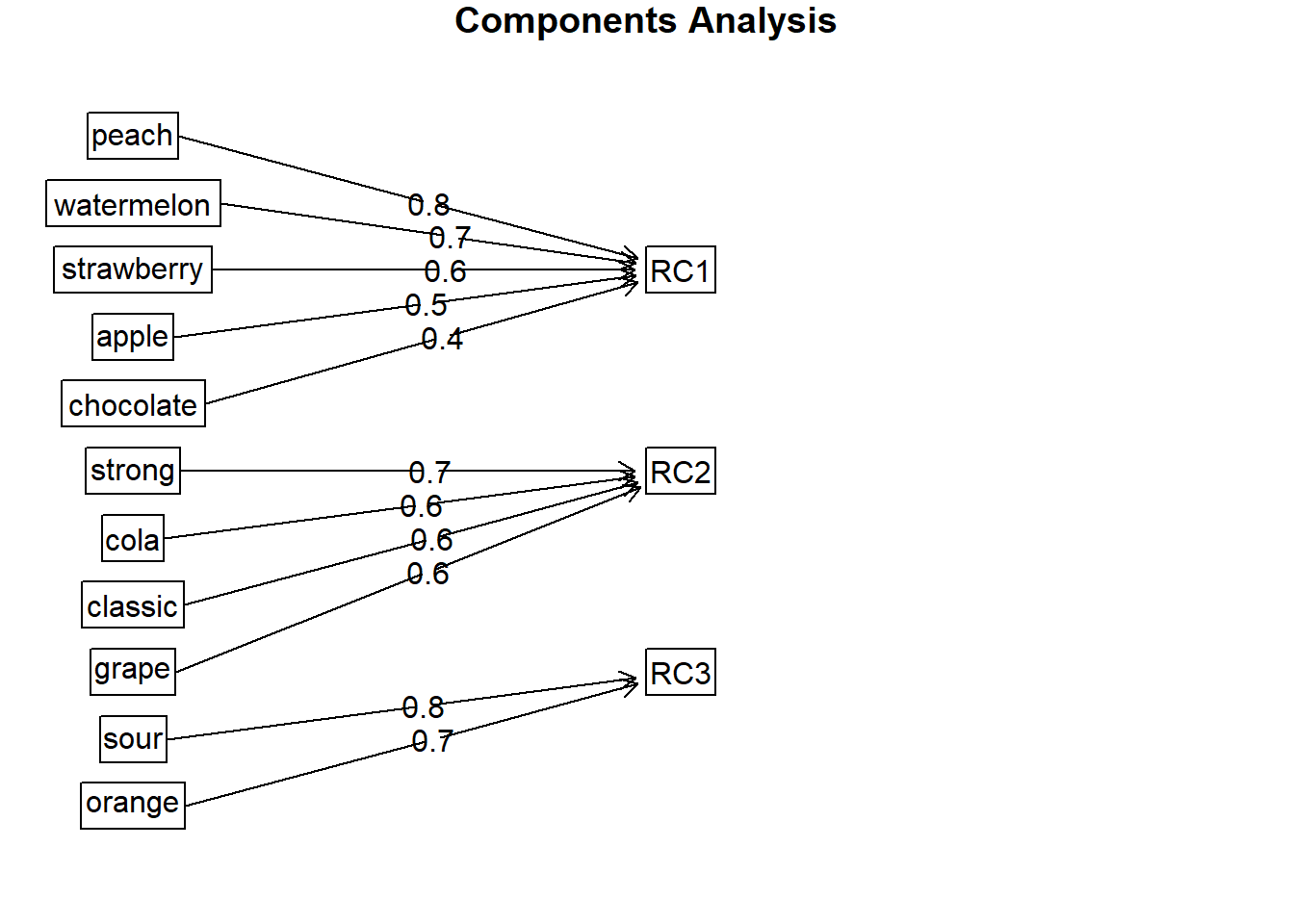
#analisis de componentes principales (psych)data <- data[,c(-1,-2)]pcaanalysis <-principal(data, nfactors =3, rotate='varimax')pcaanalysis
Principal Components Analysis
Call: principal(r = data, nfactors = 3, rotate = "varimax")
Standardized loadings (pattern matrix) based upon correlation matrix
RC1 RC2 RC3 h2 u2 com
classic -0.17 0.64 0.04 0.43 0.57 1.2
strong -0.13 0.70 0.08 0.51 0.49 1.1
grape -0.03 0.57 -0.13 0.35 0.65 1.1
sour -0.03 0.09 0.83 0.70 0.30 1.0
orange 0.24 -0.13 0.75 0.63 0.37 1.3
strawberry 0.64 -0.22 0.09 0.47 0.53 1.3
cola 0.07 0.64 -0.01 0.42 0.58 1.0
apple 0.54 0.02 0.20 0.33 0.67 1.3
chocolate 0.36 -0.08 0.02 0.13 0.87 1.1
peach 0.75 0.03 -0.01 0.57 0.43 1.0
watermelon 0.68 -0.01 -0.01 0.47 0.53 1.0
RC1 RC2 RC3
SS loadings 1.98 1.72 1.32
Proportion Var 0.18 0.16 0.12
Cumulative Var 0.18 0.34 0.46
Proportion Explained 0.39 0.34 0.26
Cumulative Proportion 0.39 0.74 1.00
Mean item complexity = 1.1
Test of the hypothesis that 3 components are sufficient.
The root mean square of the residuals (RMSR) is 0.1
with the empirical chi square 821.53 with prob < 3.5e-157
Fit based upon off diagonal values = 0.57
Las cargas para los datos se muestran a continuación y sugieren que hay tres grupos básicos de sabores: ácidos, tradicionales y los sabores de fruta y chocolate. Esto sugiere que deberíamos considerar tener uno de Sour / Orange en nuestro portafolio. Como Sour está más lejos de Strawberry (ver el análisis de correspondencia). Esto respalda aún más la opinión de que Classic + Sour + Strawberry + Cola es la mejor cartera. Los gráficos derivados de este nuevo análisis, nos revelan la estructura subyacente de los datos analizados.
biplot.psych(pcaanalysis)
plot(pcaanalysis)
cor.plot(pcaanalysis, numbers=TRUE)
fa.diagram(pcaanalysis)
Tamaño de la cartera
¿Cuántos productos?
¿Debería el fabricante de chicles ofrecer 3, 4, 5 o 6 variantes diferentes de chicle?
La forma en que se hace esta pregunta es ejecutar TURF varias veces, y luego crear una gráfica que represente la aportación de cada nueva incorporación a la cartera de producto. Como regla general, la ganancia incremental en el alcance de cada nuevo producto en la cartera es mucho menor que la anterior.
Todo parece sugerir que tres o cuatro son probablemente la mayor cantidad de productos que tienen sentido en este ejemplo, pero en última instancia, esta es una compensación que necesita considerar los costos marginales de fabricación, comercialización y distribución de cada producto adicional.
De la misma forma, se debe pensar en las restricciones. No puede ser una combinación cualquiera, sino que los dos sabores básicos de la empresa Classic y Cola deben figurar sí o sí en la combinación, siendo irrenunciable su partcipación el portfolio de prodcutos de la empresa.
Iteración del TURF
Realizando el TURF y aplicando esta restricción, la tabla resultante es esta …
Podemos observar que el alcance de esa combinación es de 74.72% de la muestra. Veamos que sucedería si decidimos añadir un nuevo sabor, pero restringiendo esta combinación.
turfprods <-turf(data, 11, 3)
3 of 11: 0.1430509 sec
total time elapsed: 0.143621 sec
turf <-as.data.frame(turfprods[["turf"]][[1]])colnames(turf)<-c('combo','rchX', 'frqX', 'classic','strong','grape','sour','orange','strawberry','cola','apple','chocolate','peach','watermelon')turf <-rows(turf, turf$classic==1& turf$cola==1) #restringe a que solo saque la combinación classic+cola y otra.turf.1b <-round((turf$rchX[[1]]-turf.1a)*100,2)turf
Podemos observar en la tabla anterior que la mejor alternativa para tener mayor alcance a elegir es incorporar al portfolio es Strawberry, con un alcance de 88.62%. Así hemos mejorado un alcance del 13.9%; ¿queremos sólo uno más o dos más?. Dando por buena esta combinación, ¿que aportaría más?
turfprods <-turf(data, 11, 4)
4 of 11: 0.395731 sec
total time elapsed: 0.3964541 sec
Ya podemos observar que la mejor alternativa sería Sour. Podríamos seguir hasta añadir las 11, pero la decisión de cuántos como ya indicamos anteriormente tiene ya que ver con otras consideraciones como los costos marginales de fabricación, comercialización y distribución de cada producto adicional.
Espero os haya gustado el post y os pueda ser de utilidad.