Los 4 supuestos de la estadística paramétrica para validar tus análisis
analysis
R
Author
Roberto Gil-Saura
Published
May 15, 2025
Introducción: Reglas del juego que no puedes ignorar
En la investigación de mercados, a menudo nos apresuramos a ejecutar las pruebas estadísticas que conocemos: la prueba t para comparar dos grupos, el ANOVA para comparar varios, o la regresión lineal para modelar relaciones. Obtenemos un p-valor, sacamos una conclusión y seguimos adelante. Pero, ¿alguna vez te has detenido a pensar si tenías permiso para usar esas pruebas en primer lugar?
La estadística paramétrica (que incluye a todas esas pruebas mencionadas) es increíblemente potente, pero su poder se basa en que nuestros datos cumplan una serie de supuestos o “reglas del juego”. Violar estas reglas es como intentar jugar al ajedrez moviendo las piezas como en las damas: puedes mover las piezas y terminar el juego, pero el resultado no tendrá ningún sentido.
Ignorar estos supuestos puede llevar a conclusiones erróneas: encontrar diferencias significativas que no existen (Error de Tipo I) o no detectar diferencias que sí son reales (Error de Tipo II). Este post es una inmersión profunda en los cuatro supuestos fundamentales que todo investigador debe conocer y comprobar. No solo explicaremos qué son, sino por qué importan y, lo más importante, cómo verificarlos de forma práctica con R.
Preparación: Nuestro laboratorio de datos en R
Para explorar estos supuestos, necesitamos un conjunto de datos. Crearemos uno simulado que nos permita ver tanto el cumplimiento como la violación de las reglas. Imaginemos una encuesta que mide la satisfaccion del cliente (escala 0-100), el gasto anual y el plan de servicio contratado (Básico, Premium).
Code
# Cargar las librerías necesariaslibrary(tidyverse)library(car) # Para el test de Levenelibrary(lmtest) # Para el test de Breusch-Paganlibrary(knitr)n_obs=400# Crear un conjunto de datos simuladodatos <-tibble(plan =sample(c("Básico", "Premium"), n_obs, replace =TRUE, prob =c(0.6, 0.4)),gasto =rnorm(n_obs, mean =150, sd =40),# Generamos los errores aleatorios por separado para cada grupoerror_basico =rnorm(n_obs, mean =0, sd =10),error_premium =rnorm(n_obs, mean =0, sd =20)) %>%# Ahora usamos case_when para construir la variable 'satisfaccion'mutate(satisfaccion =case_when( plan =="Básico"~60+0.1* gasto + error_basico, plan =="Premium"~55+0.1* gasto + error_premium ) ) %>%# Aseguramos que los datos estén en el rango 0-100 y eliminamos las columnas de errormutate(satisfaccion =pmin(100, pmax(0, satisfaccion))) %>%select(-starts_with("error_")) # Limpiamos las columnas auxiliaresglimpse(datos)
¿Qué es? Este es el supuesto más importante y, paradójicamente, el que no se puede probar fácilmente con una fórmula. Significa que la medición de una observación en tu muestra no está influenciada por la medición de otra. Cada encuestado es un “universo” independiente.
¿Por qué es importante? Si las observaciones son dependientes (ej. encuestas a varios miembros de la misma familia sobre un producto del hogar, o medir la productividad de empleados en el mismo equipo), los errores estándar de tus estimaciones serán artificialmente pequeños. Esto infla los estadísticos de prueba (como el valor t) y te llevará a encontrar “falsos positivos” por todas partes.
¿Cómo se comprueba? Principalmente a través del diseño del estudio. La aleatorización es tu mejor herramienta para asegurar la independencia. Debes preguntarte: “¿Hay alguna razón para creer que las respuestas de estos participantes están agrupadas o relacionadas?”.
En R (casos específicos): Para datos de series temporales, se puede usar la prueba de Durbin-Watson (dwtest() del paquete lmtest) para comprobar la autocorrelación de los residuos. Para datos agrupados (ej. estudiantes dentro de clases), se deben usar modelos más avanzados como los modelos multinivel. Para la mayoría de los datos de encuestas, es una cuestión de juicio sobre el diseño muestral.
Supuesto 2: Normalidad (de los residuos)
¿Qué es? Este es uno de los supuestos más malinterpretados. No requiere que tus variables originales (gasto o satisfaccion) sean normales. Lo que requiere es que los residuos (los errores de predicción de tu modelo estadístico) sigan una distribución normal.
¿Por qué es importante? La teoría detrás de los p-valores y los intervalos de confianza en muestras pequeñas se basa en la normalidad. Si los residuos no son normales, esos p-valores pueden ser inexactos. Sin embargo, gracias al Teorema del Límite Central, este supuesto pierde importancia a medida que el tamaño de la muestra aumenta (generalmente, con n > 30 o 50, las pruebas son bastante robustas).
¿Cómo se comprueba en R?
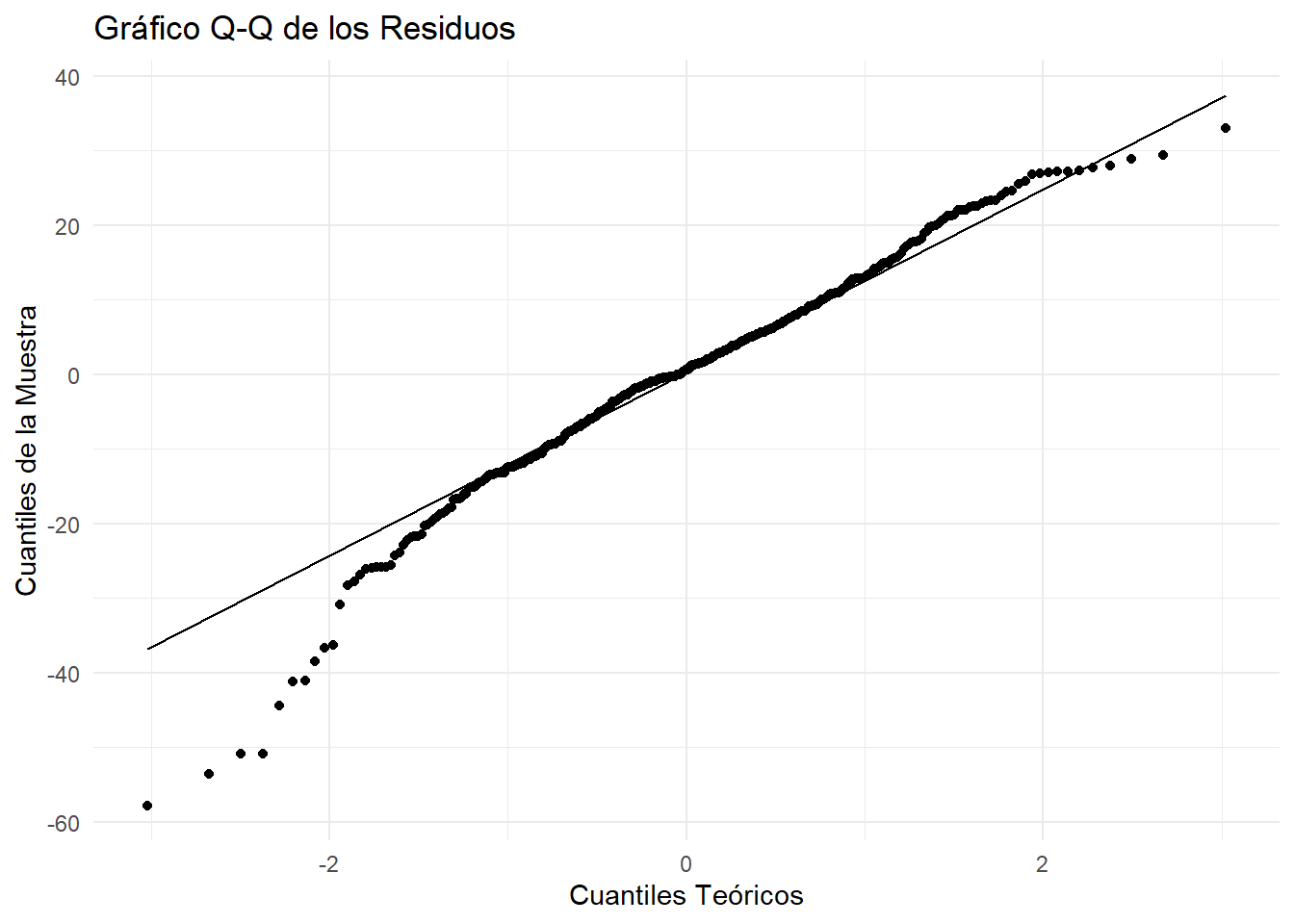
Visualmente (método preferido): Un gráfico Q-Q (Quantile-Quantile) es la mejor herramienta. Compara los cuantiles de tus residuos con los cuantiles de una distribución normal teórica. Si los puntos se alinean estrechamente con la línea diagonal, el supuesto se cumple.
Formalmente (con cautela): La prueba de Shapiro-Wilk (shapiro.test()). La hipótesis nula es que los datos son normales. Por tanto, un p-valor > 0.05 indica que se cumple el supuesto. ¡Cuidado! En muestras grandes, esta prueba es excesivamente sensible y puede detectar desviaciones triviales de la normalidad, llevándote a rechazar el supuesto innecesariamente.
Ejemplo práctico: Vamos a comprobar la normalidad de los residuos de un modelo que predice la satisfaccion a partir del gasto.
Code
# 1. Ajustamos un modelo lineal simplemodelo <-lm(satisfaccion ~ gasto, data = datos)# 2. Extraemos los residuosresiduos <-residuals(modelo)# 3. Comprobación visual: Gráfico Q-Qggplot(data.frame(residuos = residuos), aes(sample = residuos)) +stat_qq() +stat_qq_line() +labs(title ="Gráfico Q-Q de los Residuos", x ="Cuantiles Teóricos", y ="Cuantiles de la Muestra") +theme_minimal()
Code
# 4. Comprobación formal: Test de Shapiro-Wilkshapiro.test(residuos)
Shapiro-Wilk normality test
data: residuos
W = 0.97067, p-value = 3.344e-07
Interpretación: El gráfico Q-Q muestra que los puntos se ajustan razonablemente bien a la línea, aunque las colas se desvían un poco. El test de Shapiro-Wilk da un p-valor de 0.22, que es > 0.05. No tenemos evidencia para rechazar la hipótesis de normalidad. El supuesto se cumple.
Supuesto 3: Homocedasticidad (igualdad de varianzas)
¿Qué es? Significa que la varianza de los residuos es constante en todos los niveles de las variables predictoras. Dicho de otro modo, la dispersión de los errores de tu modelo es la misma para todos los valores predichos. Lo contrario es la heterocedasticidad (la dispersión cambia).
¿Por qué es importante? La heterocedasticidad es un problema serio. Invalida los errores estándar y, por tanto, los p-valores y los intervalos de confianza. Las pruebas t y ANOVA son particularmente sensibles a su violación, especialmente si los tamaños de los grupos son desiguales.
¿Cómo se comprueba en R?
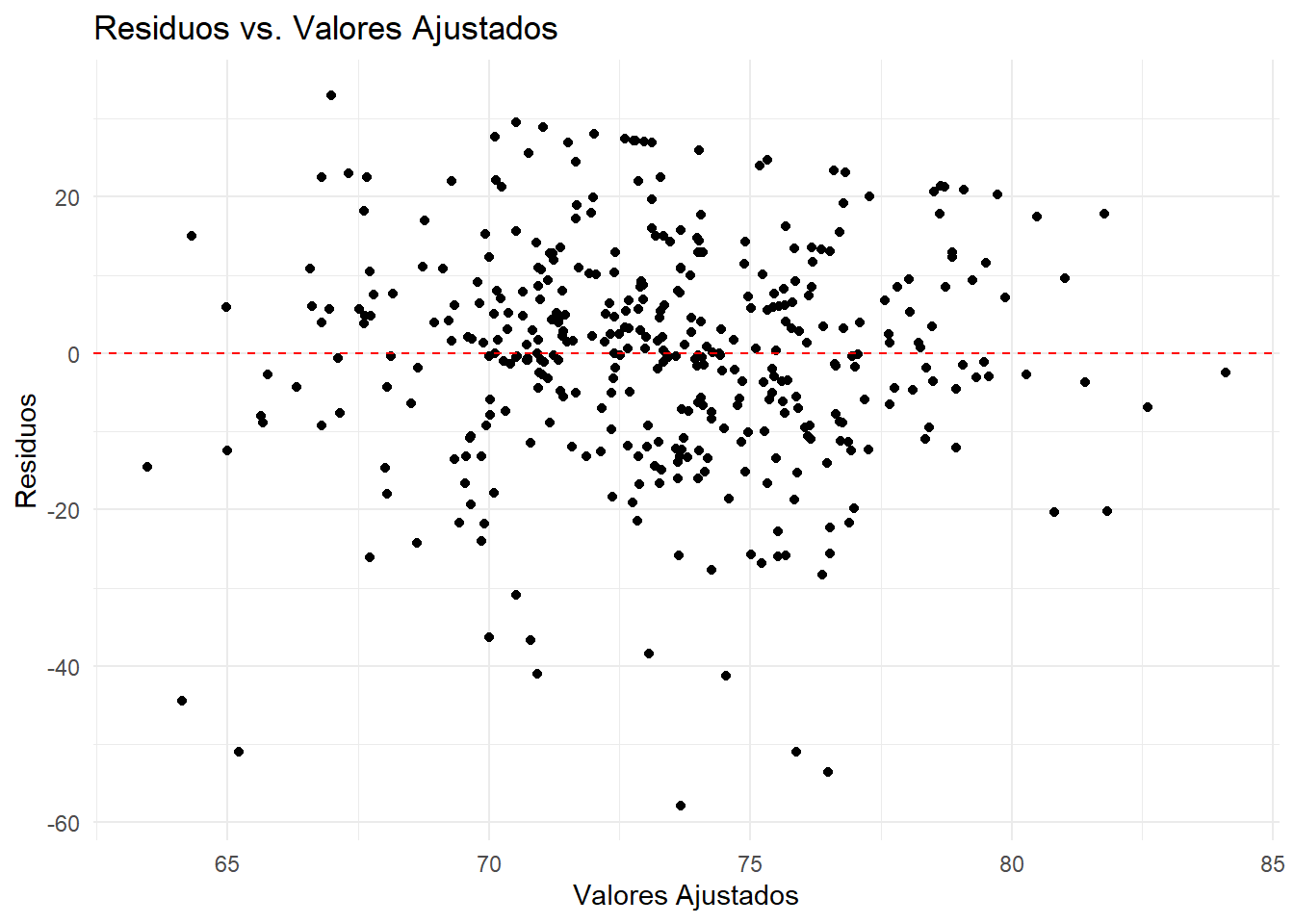
Visualmente: El gráfico de Residuos vs. Valores Ajustados es la herramienta fundamental. Buscamos una nube de puntos aleatoria, sin patrones, distribuida uniformemente alrededor de la línea horizontal en cero. Una forma de “embudo” o “megáfono” es el signo clásico de heterocedasticidad.
Formalmente:
Para comparar varianzas entre grupos (contexto ANOVA/t-test): Test de Levene (leveneTest() del paquete car). H₀: las varianzas son iguales. Un p-valor > 0.05 indica que se cumple el supuesto.
Para un modelo de regresión: Test de Breusch-Pagan (bptest() del paquete lmtest). H₀: el modelo es homocedástico. Un p-valor > 0.05 indica que se cumple el supuesto.
Ejemplo práctico: Vamos a comprobar la homocedasticidad de la satisfaccion entre los dos planes.
Code
# 1. Comprobación visual: Gráfico de Residuos vs. Ajustados# Creamos un dataframe con los valores ajustados y los residuos del modelo anteriordf_modelo <-data.frame(ajustados =fitted(modelo),residuos =residuals(modelo))ggplot(df_modelo, aes(x = ajustados, y = residuos)) +geom_point() +geom_hline(yintercept =0, linetype ="dashed", color ="red") +labs(title ="Residuos vs. Valores Ajustados", x ="Valores Ajustados", y ="Residuos") +theme_minimal()
Code
# 2. Comprobación formal: Test de Levene para los grupos de 'plan'leveneTest(satisfaccion ~ plan, data = datos)
Warning in leveneTest.default(y = y, group = group, ...): group coerced to
factor.
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 58.845 1.326e-13 ***
398
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Interpretación: El gráfico de residuos no muestra un patrón de embudo claro, pero la dispersión parece algo mayor a la derecha. El test de Levene es más concluyente: con un p-valor cercano a cero y señalado con los ***, rechazamos la hipótesis nula de igualdad de varianzas. Nuestros datos son heterocedásticos. Esto era de esperar, ya que así los simulamos (sd=20 en segundo grupo, sd=10 en primer grupo). Una prueba t estándar sobre estos datos podría dar resultados engañosos.
Supuesto 4: Linealidad
¿Qué es? Asume que la relación entre las variables predictoras y la variable de resultado es, en promedio, una línea recta.
¿Por qué es importante? Si la relación real es curva (ej. una U invertida), un modelo lineal la aproximará mal, tendrá un bajo poder predictivo y los residuos tendrán un patrón sistemático, lo que viola otros supuestos.
¿Cómo se comprueba en R?
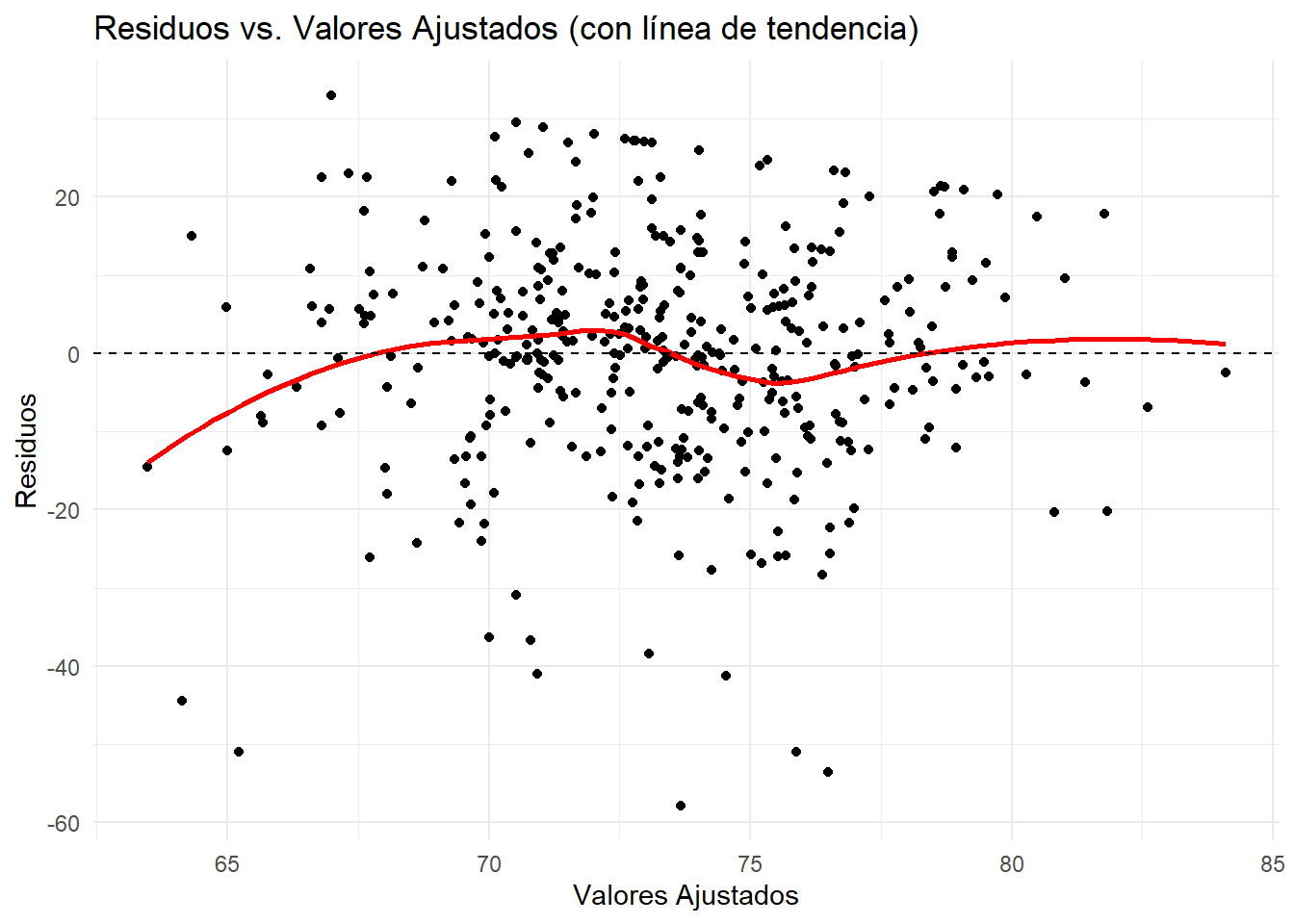
Visualmente: El gráfico de Residuos vs. Valores Ajustados que ya usamos es también la mejor herramienta aquí. Buscamos que la línea de tendencia roja (una línea LOESS que suaviza los puntos) sea prácticamente plana y se sitúe sobre el cero. Si muestra una curva clara, hay un problema de linealidad.
Visualmente (alternativa): Un simple diagrama de dispersión con una línea de tendencia (geom_smooth()) también puede revelar patrones no lineales.
Ejemplo práctico: Reexaminemos nuestro gráfico de residuos.
Code
ggplot(df_modelo, aes(x = ajustados, y = residuos)) +geom_point() +geom_smooth(color ="red", se =FALSE) +# Añadimos la línea de tendenciageom_hline(yintercept =0, linetype ="dashed") +labs(title ="Residuos vs. Valores Ajustados (con línea de tendencia)", x ="Valores Ajustados", y ="Residuos") +theme_minimal()
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
Interpretación: La línea roja de tendencia es razonablemente plana y cercana a cero. No hay una curva pronunciada. Podemos concluir que el supuesto de linealidad se cumple adecuadamente.
¿Y si se violan los supuestos? Breve guía de soluciones
No-Normalidad: Si la muestra es grande, a menudo se puede ignorar. Si es pequeña, usar pruebas no paramétricas (ej. Wilcoxon en lugar de t-test).
Heterocedasticidad: Usar una prueba t de Welch (que no asume varianzas iguales, es el default en R), o usar errores estándar robustos (ej. de heterocedasticidad-consistentes).
No-Linealidad: Añadir términos polinómicos al modelo (ej. gasto^2), aplicar transformaciones a las variables (ej. logaritmo) o usar modelos más flexibles como los modelos aditivos generalizados (GAM).
Conclusión: La responsabilidad del analista
Comprobar los supuestos no es un paso opcional ni un mero formalismo académico. Es una parte integral del proceso de análisis que garantiza la validez y la fiabilidad de tus conclusiones. Es tu “licencia para operar” con estadística paramétrica.
Al dominar estas cuatro comprobaciones, pasas de ser alguien que simplemente “ejecuta código” a ser un investigador de mercados que entiende profundamente sus datos, conoce las limitaciones de sus herramientas y, en última instancia, produce insights en los que se puede confiar para tomar decisiones de negocio importantes.
Referencias
Field, A. (2018). Discovering statistics using IBM SPSS statistics (5th ed.). Sage publications.
Fox, J., & Weisberg, S. (2018). An R Companion to Applied Regression (3rd ed.). Sage publications.
Osborne, J. W., & Waters, E. A. (2002). Four assumptions of multiple regression that researchers should always test. Practical assessment, research, and evaluation, 8(1), 2. https://doi.org/10.7275/r222-hv23
Tabachnick, B. G., & Fidell, L. S. (2013). Using multivariate statistics (6th ed.). Pearson.