Introducción, ¿datos con error?
Imagina que acabas de realizar una encuesta a 400 clientes y descubres que su gasto medio mensual es de 52€. Es un dato interesante, pero inmediatamente surge una pregunta fundamental: ¿Qué tan fiable es este número? Si hubieras encuestado a otros 400 clientes, ¿habrías obtenido 52€, o quizás 50€, o 55€? ¿Representa este 52€ de tu muestra el gasto medio real de todos tus miles de clientes?
Esta incertidumbre es el corazón del muestreo estadístico. Nunca podemos estar 100% seguros del valor verdadero de la población, pero sí podemos medir y cuantificar nuestra incertidumbre. La métrica que nos permite hacer esto, la verdadera “regla para medir la incertidumbre”, es el Error Estándar (EE).
Comprender el Error Estándar no es un mero ejercicio académico; es la habilidad que te permite interpretar cualquier resultado de una encuesta, test A/B o estudio de mercado con el rigor de un verdadero profesional. Este post es una inmersión profunda en este concepto. No solo lo definiremos, sino que lo veremos “nacer” a través de una simulación en R, demostrando visualmente su conexión inseparable con el muestreo y los intervalos de confianza.
Parte I: La conceptualización - ¿Qué es (y qué no es) el error estándar?
El error estándar es un concepto que a menudo se confunde con la desviación estándar. Aclarar esta diferencia es el primer y más importante paso.
La desviación estándar: La variabilidad DENTRO de tu muestra
Imagina tu muestra de 400 clientes. Algunos gastan 20€, otros 80€. La desviación estándar (DE) mide esta dispersión; te dice, en promedio, cuánto se alejan los gastos de los clientes individuales de la media de 52€ de tu muestra. Es una medida de la heterogeneidad de tus datos.
El error estándar: La variabilidad ENTRE muestras
Ahora, imagina un ejercicio mental. Repites tu encuesta no una, sino 10.000 veces, cada vez con una nueva muestra aleatoria de 400 clientes. Obtendrías 10.000 medias de gasto ligeramente diferentes: 52.1€, 51.8€, 52.5€, etc.
El Error Estándar (EE) es la desviación estándar de todas esas medias muestrales hipotéticas.
Piensa en esta analogía: * Un pescador lanza una red (tu encuesta) y recoge 400 peces (tu muestra). La Desviación Estándar es la variabilidad en el tamaño de los peces dentro de esa red. * El Error Estándar es la variabilidad en el tamaño medio de los peces que obtendría si lanzara la red 10.000 veces en el mismo lago. Mide la precisión de tu estimación de la media.
| Concepto | ¿Qué mide? | ¿A qué se aplica? |
|---|---|---|
| Desviación Estándar (DE) | La dispersión de los datos individuales. | A una única muestra. |
| Error Estándar (EE) | La precisión de la media muestral como estimación. | Al proceso de muestreo en sí. |
Parte II: La anatomía del error estándar
La eficacia del error estándar es que, aunque su definición es conceptual, no necesitamos realizar miles de encuestas para calcularlo. La estadística nos proporciona una fórmula elegante para estimarlo a partir de una sola muestra:
\[ \text{Error Estándar (EE)} = \frac{\sigma}{\sqrt{n}} \]
Donde: * σ (sigma) es la desviación estándar de la población. Como casi nunca la conocemos, la estimamos con la desviación estándar de nuestra muestra (s). * n es el tamaño de nuestra muestra.
Analicemos sus dos componentes, porque nos enseñan todo lo que necesitamos saber sobre la precisión:
- El numerador (σ): La variabilidad inherente de la población. Si todos tus clientes gastaran casi lo mismo (baja σ), cualquier muestra que tomes te dará una media muy parecida. Si tus clientes son muy heterogéneos (alta σ), las medias de tus muestras variarán mucho más. Esto es algo que no puedes controlar, es una característica de la población que estudias.
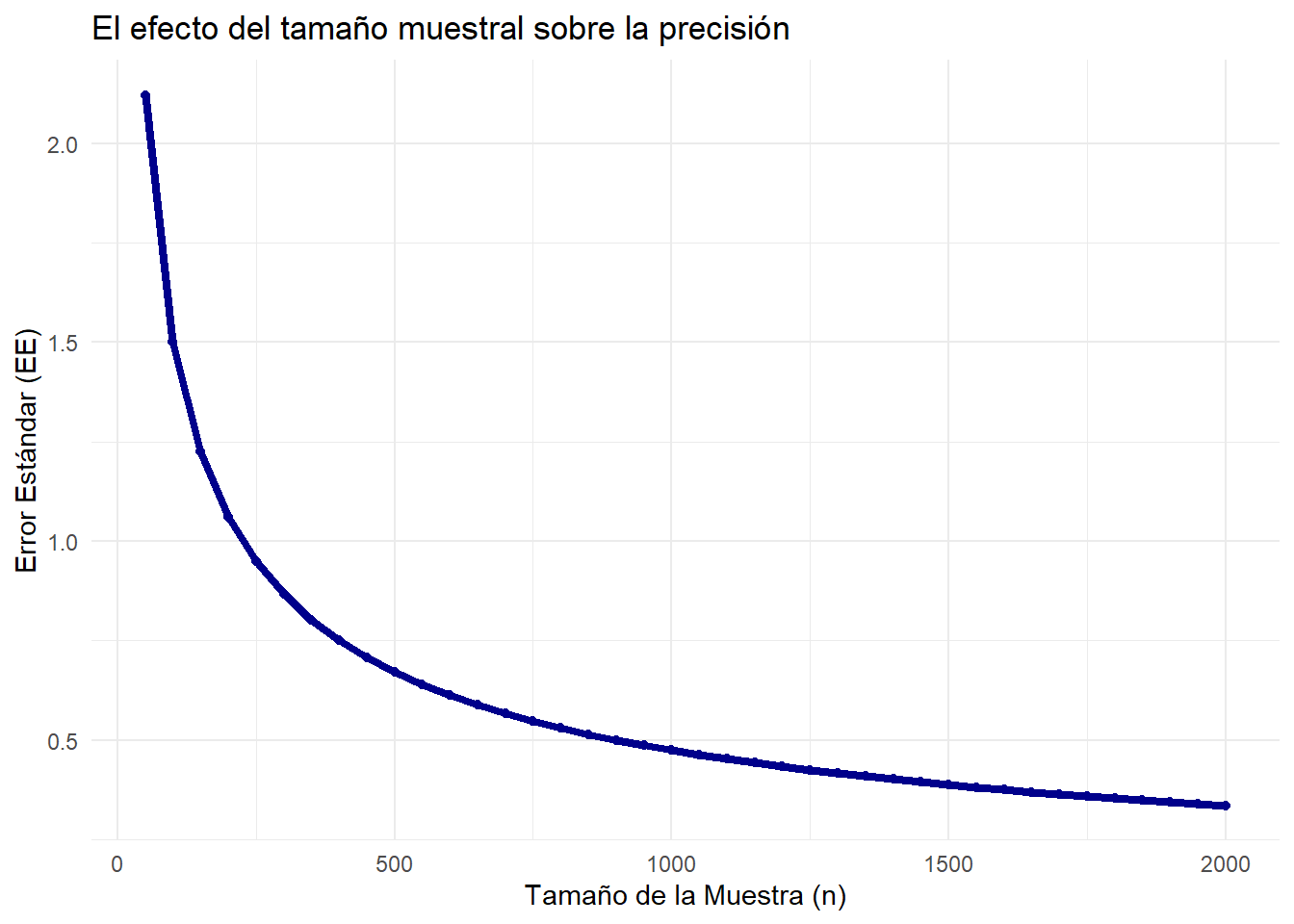
- El denominador (√n): El poder que tienes como investigador. Fíjate que el tamaño de la muestra está en el denominador. Esto significa que a medida que aumentas el tamaño de tu muestra (n), el error estándar disminuye drásticamente. Esta es la justificación matemática de por qué las muestras más grandes producen estimaciones más precisas.
El gráfico muestra que los mayores beneficios en precisión se obtienen al principio. Pasar de n=50 a n=400 reduce el error enormemente. Pasar de n=1600 a n=2000 lo reduce, pero mucho menos.
Parte III: Del error estándar al intervalo de confianza
El Error Estándar por sí solo es un número útil, pero su verdadera aplicación práctica es ser el bloque de construcción del Intervalo de Confianza (IC).
Un intervalo de confianza toma nuestra estimación puntual (la media de 52€) y construye un rango a su alrededor que, con un cierto nivel de confianza (normalmente el 95%), probablemente contiene el verdadero valor de la población.
La fórmula es simple:
\[ \text{Intervalo de Confianza} = \text{Media de la muestra} \pm (\text{Valor crítico} \times \text{Error Estándar}) \]
- El valor crítico proviene de una distribución teórica (normalmente la t de Student o la normal). Para un IC del 95%, este valor es aproximadamente 1.96.
Así que, si nuestro EE es de 0.75€, el IC del 95% para nuestro gasto medio de 52€ sería: 52€ ± (1.96 * 0.75€) = 52€ ± 1.47€ Esto nos da un rango de [50.53€, 53.47€].
La interpretación correcta es: “Con un 95% de confianza, podemos afirmar que el gasto medio real de toda nuestra población de clientes se encuentra entre 50.53€ y 53.47€”.
Parte IV: Simulación en R
La teoría está muy bien, pero para creer en él, y para que el concepto se asiente de verdad, vamos a simularlo. Crearemos una población “real”, tomaremos miles de muestras y veremos si la teoría se cumple.
Paso 1: Crear nuestra población “real”
Imaginemos que nuestra empresa tiene 100.000 clientes. Vamos a simular su gasto mensual. En este universo simulado, nosotros somos “los que lo saben todo”: conocemos la media y la desviación estándar verdaderas de la población.
library(tidyverse)
set.seed(42)
# Parámetros de la población
tamano_poblacion <- 100000
media_real_poblacion <- 50 # La verdad absoluta que queremos descubrir
sd_real_poblacion <- 15
# Creamos la población
poblacion <- tibble(
gasto = rnorm(tamano_poblacion, mean = media_real_poblacion, sd = sd_real_poblacion)
)
# Resumen de nuestra "verdad"
summary(poblacion$gasto) Min. 1st Qu. Median Mean 3rd Qu. Max.
-10.65 39.76 49.97 49.94 60.10 114.92 Nuestra media real es 50.04€. Este es el número que una encuesta perfecta debería encontrar.
Paso 2: Tomar UNA muestra y analizarla
Ahora actuamos como un investigador normal. Tomamos una muestra aleatoria de 400 clientes y la analizamos, sin saber nada de la población real.
tamano_muestra <- 400
# Tomamos una muestra
una_muestra <- poblacion %>%
sample_n(size = tamano_muestra)
# Calculamos sus estadísticos
media_muestra <- mean(una_muestra$gasto)
sd_muestra <- sd(una_muestra$gasto)
error_estandar_calculado <- sd_muestra / sqrt(tamano_muestra)
cat(paste("Media de la muestra:", round(media_muestra, 2), "€\n"))Media de la muestra: 50.62 €cat(paste("Desviación Estándar de la muestra:", round(sd_muestra, 2), "€\n"))Desviación Estándar de la muestra: 14.2 €cat(paste("Error Estándar calculado a partir de la muestra:", round(error_estandar_calculado, 2), "€\n"))Error Estándar calculado a partir de la muestra: 0.71 €Fíjate: nuestra media muestral (50.51€) está cerca, pero no es exactamente igual a la media real (50.04€). El Error Estándar calculado es de 0.74€.
Hasta aquí, es lo que hacemos en el mundo real. El investigador sólo tiene presupuesto para hacer una encuesta - una muestra no centrnares o miles. Eso sólo lo puede hacer en un ejercicio de laboratorio con una población real.
Paso 3: El proceso de simulación - Tomar 10.000 muestras
Per como esto es laboratorio, vamos a hacer lo que en la vida real es imposible: repetir la encuesta 10.000 veces.
n_simulaciones <- 10000
# Usamos 'replicate' para repetir el proceso de muestreo
medias_muestrales <- replicate(n_simulaciones, {
muestra <- poblacion %>% sample_n(size = tamano_muestra)
mean(muestra$gasto)
})
# Creamos un dataframe con nuestros resultados
df_medias <- tibble(media = medias_muestrales)Paso 4: La revelación - Visualizando la distribución muestral
Vamos a crear un histograma de las 10.000 medias que hemos obtenido. Este gráfico es la distribución muestral de la media, el concepto teórico que hemos traído a la vida.
# Calculamos la desviación estándar de nuestras 10.000 medias
# Esto es el Error Estándar "real" o empírico
error_estandar_empirico <- sd(df_medias$media)
# Construimos el intervalo de confianza teórico
ic_inferior <- media_real_poblacion - 1.96 * error_estandar_calculado
ic_superior <- media_real_poblacion + 1.96 * error_estandar_calculado
ggplot(df_medias, aes(x = media)) +
geom_histogram(bins = 50, fill = "steelblue", color = "gray", alpha = 0.8) +
# La verdad
geom_vline(xintercept = media_real_poblacion, color = "firebrick", linetype = "solid", linewidth = 1.5) +
# Los límites del IC del 95%
geom_vline(xintercept = c(ic_inferior, ic_superior), color = "seagreen", linewidth = 1) +
annotate("rect", xmin = ic_inferior, xmax = ic_superior, ymin = 0, ymax = Inf, alpha = 0.3, fill = "lightgray") +
labs(
title = "Visualización de la Distribución Muestral y el Error Estándar",
subtitle = paste0(
"EE calculado de una muestra: ", round(error_estandar_calculado, 3),
" | EE empírico de 10k muestras: ", round(error_estandar_empirico, 3)
),
x = "Media de Gasto de la Muestra (€)",
y = "Frecuencia",
caption = "La línea roja es la media real de la población. El área verde representa el Intervalo de Confianza del 95%."
) +
theme_minimal()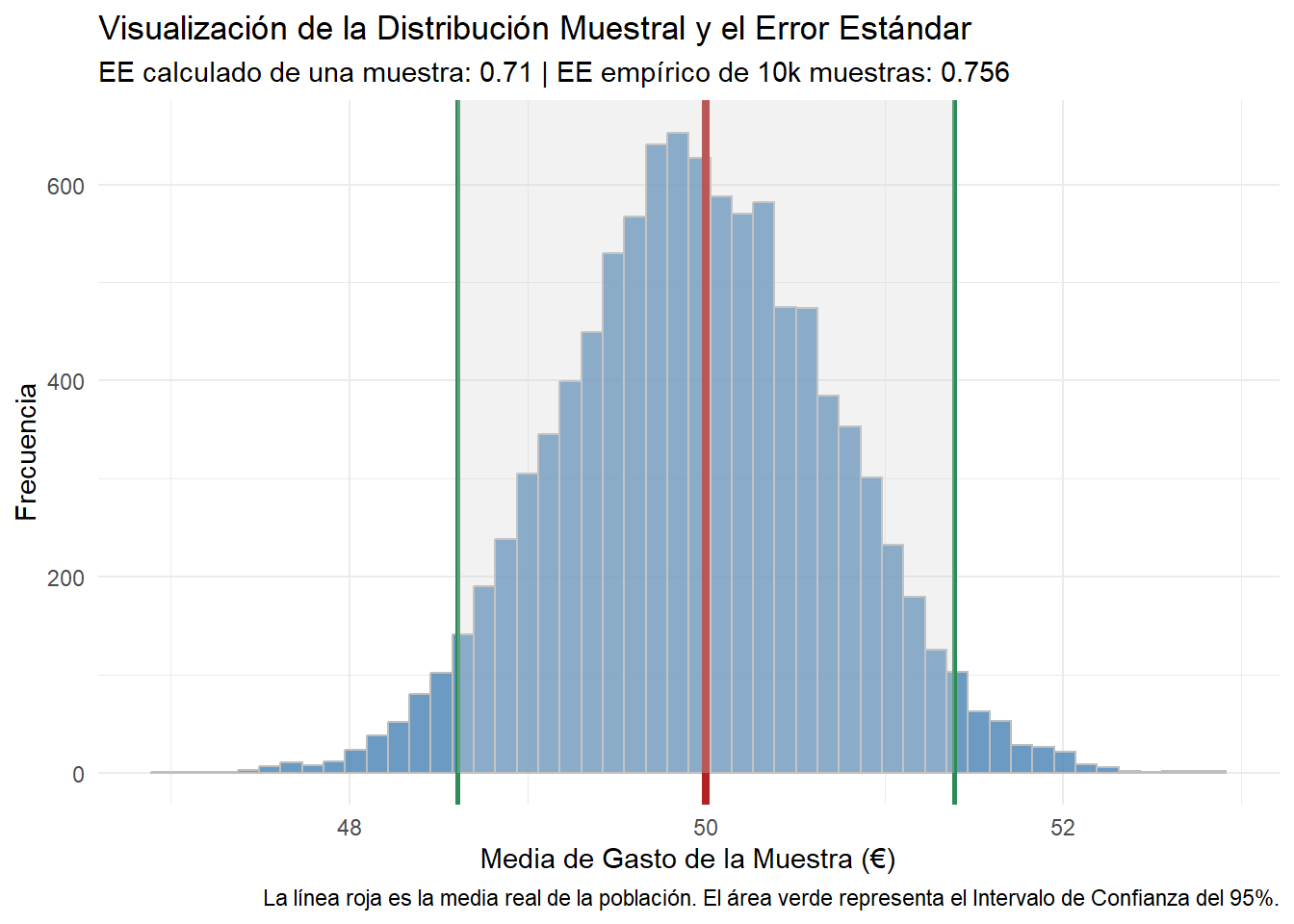
La revelación es explicativa:
- El Error Estándar que calculamos a partir de una sola muestra (0.74€) es prácticamente idéntico a la desviación estándar real de las 10.000 medias muestrales (0.749€). Podemos afirmar, pues que la fórmula funciona.
- La distribución de las medias muestrales es perfectamente normal, centrada en la media real de la población (gracias al Teorema del Límite Central), se aasemeja a la famosa campana de Gauss.
- El 95% de las medias de nuestras 10.000 encuestas han caído dentro del intervalo de confianza que construimos. Esto demuestra visualmente lo que significa “95% de confianza”.
Conclusión: El error estándar como tu guía
El Error Estándar no es solo una fórmula; es una medida fundamental de la fiabilidad de tu investigación. Es la brújula que te guía a través de la incertidumbre del muestreo.
Comprenderlo te permite: * Evaluar la precisión de tus estimaciones. * Calcular intervalos de confianza para comunicar tus resultados con honestidad intelectual. * Determinar el tamaño de muestra necesario para alcanzar un nivel de precisión deseado.
La próxima vez que veas una media en un informe, no la tomes como un hecho absoluto. Pregúntate por su error estándar. Ese pequeño número contiene toda la historia sobre la fiabilidad de los datos que tienes delante.
Referencias
Lohr, S. L. (2019). Sampling: Design and Analysis (2nd ed.). Chapman and Hall/CRC.
Moore, D. S., Notz, W. I., & Fligner, M. A. (2013). The basic practice of statistics. W. H. Freeman and Company.
Streiner, D. L. (1996). Maintaining standards: differences between the standard deviation and standard error, and when to use each. The Canadian Journal of Psychiatry, 41(8), 498-502. https://doi.org/10.1177/070674379604100806