Pearson, Spearman o Kendall: ¿Qué Correlación Usar con Datos de Encuestas? Guía Práctica en R
R
analysis
mrx
Author
Roberto Gil-Saura
Published
October 15, 2025
Introducción: relaciones entre variables
Imagina que acabas de cerrar el trabajo de campo de una importante encuesta de satisfacción de clientes. Tienes cientos de respuestas y una hipótesis clara en mente: “Los clientes que valoran mejor nuestro servicio de atención al cliente, ¿son también los más leales a nuestra marca?”. En tu cabeza, la palabra “relación” te lleva directamente a “correlación”.
Abres R, cargas tus datos y te dispones a calcularla. Pero entonces surge la duda: ¿qué función uso? ¿cor() con el método de Pearson por defecto? ¿O debería usar Spearman? ¿O quizás Kendall?
Esta no es una pregunta trivial. Elegir el test de correlación incorrecto no solo es una mala práctica estadística, sino que puede llevarte a conclusiones equivocadas, reportando una relación más débil o más fuerte de lo que realmente es, o incluso pasando por alto una relación existente.
En este post, vamos a desmitificar las tres correlaciones más famosas: la de Pearson (paramétrica), y las no paramétricas Spearman y Kendall. Entenderás sus diferencias fundamentales, aprenderás a decidir cuál usar según la naturaleza de tus datos (¡hola, escalas Likert!) y lo aplicaremos todo en un ejemplo práctico en R, como siempre, enfocado en un problema real de investigación de mercados.
Conceptualización Teórica
La decisión de usar Pearson, Spearman o Kendall depende casi por completo de si tus datos cumplen ciertos supuestos y de la naturaleza de tu muestra (Field 2012)
Correlación de Pearson (r): estándar paramétrico
La correlación de Pearson es la más conocida. Mide la fuerza y dirección de una relación lineal entre dos variables. Piensa en una línea recta: Pearson te dice qué tan bien se ajustan tus datos a esa línea. Para poder usarla, tus datos deben ser continuos (intervalo/ratio), seguir una distribución normal, tener una relación lineal y ser sensibles a los outliers. En el mundo de las encuestas, rara vez se cumplen todas estas condiciones.
Correlación de Spearman y Kendall, alternativas no paramétricas
Cuando tus datos son ordinales (como las escalas Likert), no siguen una distribución normal o tienen outliers, necesitas alternativas no paramétricas. Tanto Spearman (Spearman 1904) como Kendall (Kendall 1938) trabajan con los rangos de los datos, no con sus valores brutos.
Correlación de Spearman (rho, ρ), correlación de los rangos
La correlación de Spearman es muy intuitiva: simplemente calcula la correlación de Pearson sobre los rangos de los datos. Es decir, ordena los valores de cada variable de menor a mayor y trabaja con esas posiciones.
Esto le da sus ventajas: * Ideal para Datos Ordinales: Perfecta para escalas Likert. * Mide Relaciones Monotónicas: No exige linealidad. Solo necesita que, a medida que una variable aumenta, la otra tienda a hacer lo mismo (o lo contrario), sin importar si es a un ritmo constante. * Robusta frente a Outliers: Un valor extremo no distorsiona el cálculo tanto como en Pearson.
Tau-b de Kendall (τ), la presencia empates, concordancias y discordancias
El coeficiente Tau-b de Kendall tiene un enfoque diferente y muy elegante. En lugar de mirar los rangos directamente, analiza todos los pares de observaciones posibles y los clasifica como: * Pares Concordantes: Si para un par de sujetos, el que tiene un valor más alto en la variable X también lo tiene en la variable Y. * Pares Discordantes: Si el que tiene un valor más alto en X tiene un valor más bajo en Y. * Empates (Ties): Si tienen el mismo valor en X o en Y.
Tau-b se calcula como (Nº Pares Concordantes - Nº Pares Discordantes) dividido por una fórmula que tiene en cuenta los empates.
¿Cuándo es mejor Kendall que Spearman? 1. Muestras Pequeñas: Kendall es a menudo preferido para tamaños de muestra pequeños, ya que se considera que tiene mejores propiedades estadísticas. 2. Muchos Empates: Esta es la clave para los datos de encuestas. Una escala de 1 a 5 tendrá muchísimos valores repetidos (empates). El Tau-b de Kendall está diseñado específicamente para manejar estos empates de forma más precisa que Spearman, lo que lo convierte, teóricamente, en una opción más robusta para datos de escalas Likert. 3. Interpretación: El valor de Tau-b tiene una interpretación probabilística directa: es la diferencia entre la probabilidad de que dos pares sean concordantes y la probabilidad de que sean discordantes.
Característica
Correlación de Pearson (r)
Correlación de Spearman (ρ)
Tau-b de Kendall (τ)
Principio Cálculo
Valores brutos
Correlación de Pearson en los rangos
Pares concordantes y discordantes
Tipo de Relación
Lineal
Monotónica (lineal o no lineal)
Monotónica (lineal o no lineal)
Tipo de Datos
Intervalo o Ratio (continuos)
Ordinal, Intervalo o Ratio
Ordinal, Intervalo o Ratio
Sensibilidad Outliers
Alta
Baja
Muy Baja
Mejor para…
Datos continuos y “limpios”
Datos ordinales y de rangos en general
Muestras pequeñas y/o con muchos empates
Ejemplo Práctico en R
Vamos a resolver nuestro problema inicial, pero esta vez calcularemos los tres coeficientes para comparar sus resultados.
1. Preparación: Carga de Librerías y Datos
El código para generar los datos es el mismo que antes, incluyendo los outliers para poner a prueba los métodos.
# Cargar librerías necesariaslibrary(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.1 ✔ stringr 1.5.2
✔ ggplot2 4.0.0 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.1.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(ggpubr) # Para añadir correlaciones a los gráficoslibrary(scales)
Adjuntando el paquete: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
# Fijar una semilla para que los resultados sean reproduciblesset.seed(123)# Simular datos de encuesta (n=150) + 2 outliersn_clientes <-150datos_encuesta <-tibble(id_cliente =1:n_clientes,satisfaccion_servicio =sample(1:5, n_clientes, replace =TRUE, prob =c(0.1, 0.1, 0.2, 0.3, 0.3)),lealtad_marca =round(satisfaccion_servicio *0.8+rnorm(n_clientes, mean =0.5, sd =1))) %>%mutate(lealtad_marca =case_when( lealtad_marca <1~1, lealtad_marca >5~5,TRUE~ lealtad_marca ) ) %>%add_row(id_cliente =151, satisfaccion_servicio =1, lealtad_marca =5) %>%add_row(id_cliente =152, satisfaccion_servicio =5, lealtad_marca =1)# Vistazo a los datoshead(datos_encuesta)
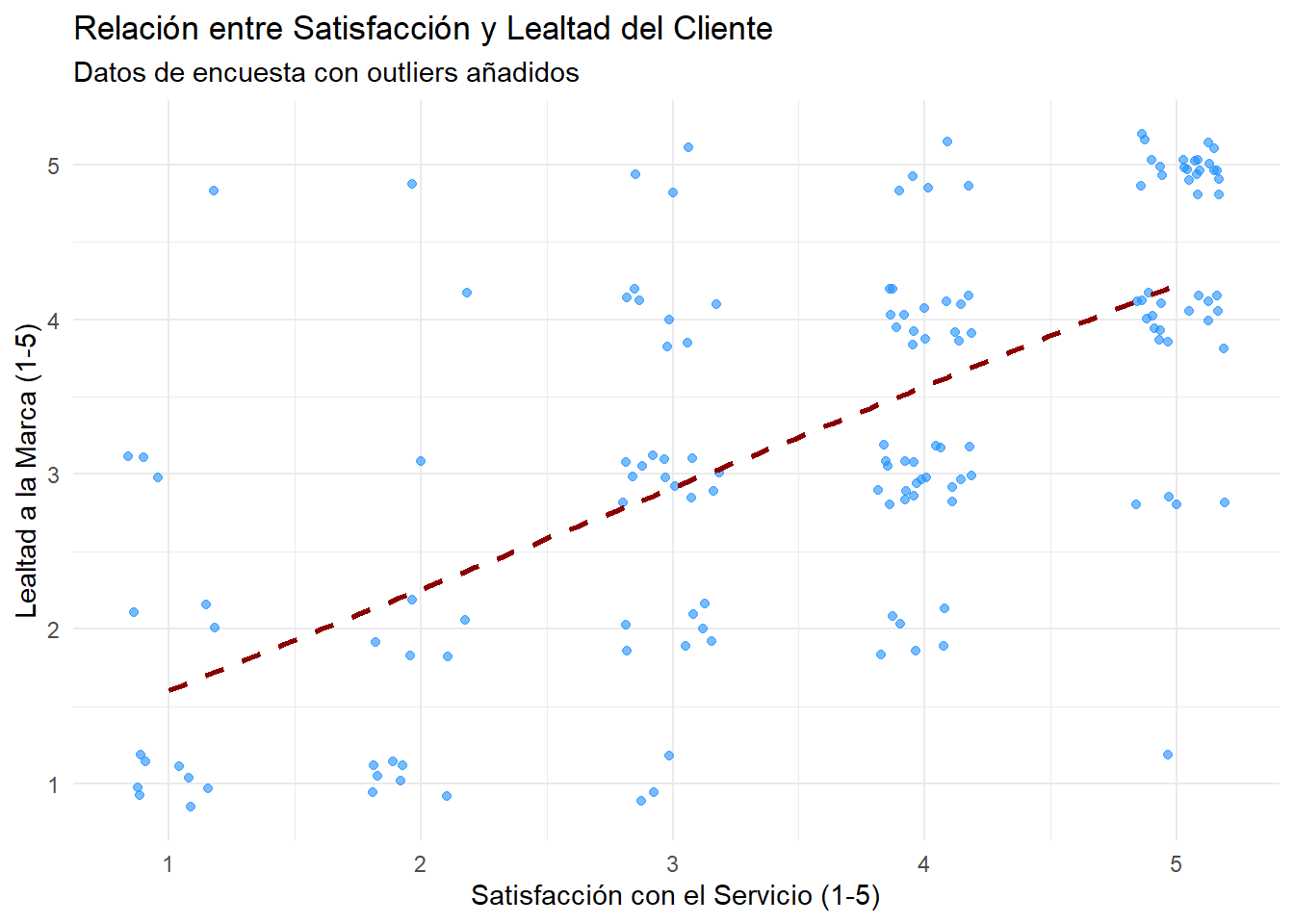
El diagrama de dispersión sigue siendo nuestro punto de partida fundamental.
# Crear el gráfico de dispersión con geom_jitterggplot(datos_encuesta, aes(x = satisfaccion_servicio, y = lealtad_marca)) +geom_jitter(width =0.2, height =0.2, alpha =0.6, color ="dodgerblue") +geom_smooth(method ="lm", se =FALSE, color ="darkred", linetype ="dashed") +labs(title ="Relación entre Satisfacción y Lealtad del Cliente",subtitle ="Datos de encuesta con outliers añadidos",x ="Satisfacción con el Servicio (1-5)",y ="Lealtad a la Marca (1-5)" ) +theme_minimal()
`geom_smooth()` using formula = 'y ~ x'
La visualización confirma una tendencia positiva general, pero también la presencia de outliers y la naturaleza discreta de nuestros datos. Esto ya nos indica la preacución con Pearson.
3. Cálculo de Correlaciones
Ahora, calculemos los tres coeficientes.
# 1. Correlación de Pearsontest_pearson <-cor.test(datos_encuesta$satisfaccion_servicio, datos_encuesta$lealtad_marca, method ="pearson")# 2. Correlación de Spearmantest_spearman <-cor.test(datos_encuesta$satisfaccion_servicio, datos_encuesta$lealtad_marca, method ="spearman", exact =FALSE)# 3. Correlación Tau-b de Kendalltest_kendall <-cor.test(datos_encuesta$satisfaccion_servicio, datos_encuesta$lealtad_marca, method ="kendall")knitr::asis_output("#### Resultados de las Correlaciones")
Resultados de las Correlaciones
cat("Coeficiente r de Pearson:", round(test_pearson$estimate, 3), "(p-valor:", scales::pvalue(test_pearson$p.value, accuracy =0.001), ")\n")
Coeficiente r de Pearson: 0.647 (p-valor: <0.001 )
Coeficiente rho de Spearman: 0.64 (p-valor: <0.001 )
cat("Coeficiente tau de Kendall:", round(test_kendall$estimate, 3), "(p-valor:", scales::pvalue(test_kendall$p.value, accuracy =0.001), ")\n")
Coeficiente tau de Kendall: 0.56 (p-valor: <0.001 )
Interpretación
Hemos obtenido tres coeficientes, todos estadísticamente significativos, pero con magnitudes diferentes.
¿Qué nos dice esta diferencia?
Pearson vs. No Paramétricos: Como esperábamos, Pearson da el valor más bajo porque los outliers y la falta de linealidad estricta lo penalizan. Claramente, no es la mejor opción aquí.
Spearman vs. Kendall: Es normal y esperable que el valor de Tau de Kendall sea inferior al de Rho de Spearman. No significa que la relación sea “más débil”. Son escalas diferentes. No debes comparar directamente sus magnitudes, sino su significancia. Ambos nos dicen lo mismo, que existe una fuerte relación monotónica positiva.
En este contexto, tanto Spearman como Kendall son opciones válidas y muy superiores a Pearson. Sin embargo, si queremos ser lo más rigurosos posible: Tau-b de Kendall es, desde un punto de vista teórico, el coeficiente más adecuado para este conjunto de datos. La razón principal es su manejo superior de los empates, que son extremadamente comunes en escalas de tipo Likert.
Por tanto, nuestra conclusión final podría ser: “se utilizó el coeficiente de correlación Tau-b de Kendall para evaluar la relación entre la satisfacción con el servicio al cliente y la lealtad a la marca, debido a la naturaleza ordinal de los datos y la presencia de numerosos empates. Se encontró una correlación positiva, moderada y estadísticamente significativa (τ = 0.56, p < 0.001). Este resultado indica que los clientes con mayores niveles de satisfacción tienden a mostrar una mayor lealtad hacia la marca.”
En resumen, el flujo de trabajo debería ser:
¿Son mis datos continuos, normales y lineales?
Sí: Usa Pearson.
No (son ordinales, no normales, etc.): Pasa al punto 2.
¿Qué sabemos acerca la muestra y los empates?
¿Tengo una muestra grande y pocos empates?Usa Spearman. Es muy popular y fácil de interpretar como “la correlación sobre los rangos”.
¿Tengo una muestra pequeña o muchos empates (ej. datos de escalas Likert)? Usa Kendall. Es la opción más robusta y teóricamente sólida en este escenario.
Dominar estas tres herramientas permite analizar relaciones con mucha más confianza y precisión, asegurando que tus conclusiones se basen en el método estadístico más apropiado para tus datos.
References
Field, Andy. 2012. Discovering Statistics Using R. Sage Publications.
Spearman, Charles. 1904. “The Proof and Measurement of Association Between Two Things.”The American Journal of Psychology 15 (1): 72–101. https://doi.org/10.2307/1412159.