Code
# Cargar la librería
library(tidyverse)
# Gráfico de barras usando geom_bar()
ggplot(data = mpg, mapping = aes(x = class)) +
geom_bar()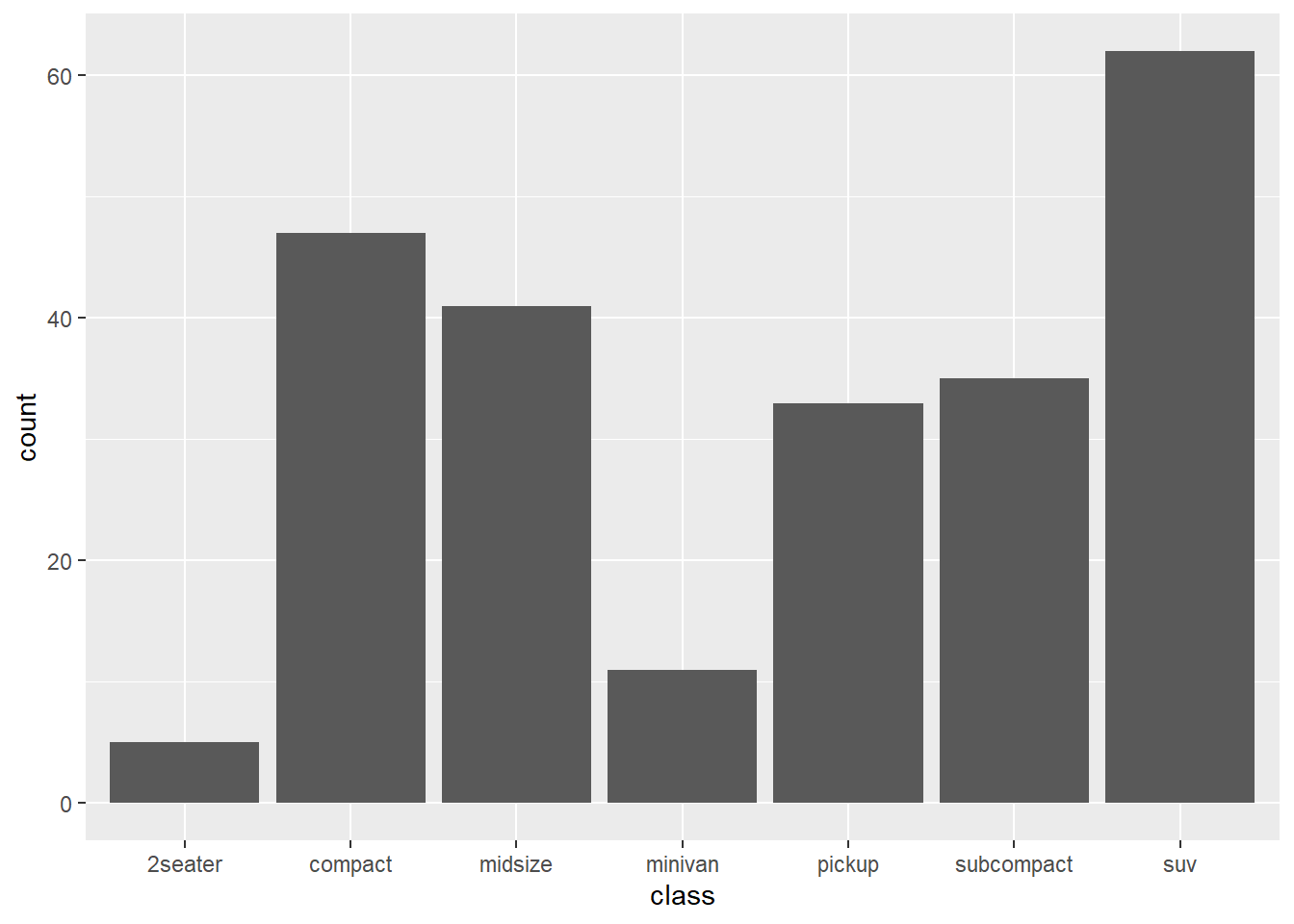
![]()
En el primer post de esta serie, descubrimos la filosofía detrás de ggplot2: la Gramática de los Gráficos. Aprendimos que cada visualización se construye a partir de tres componentes esenciales: los datos, las estéticas (aes) y las geometrías (geom). Con esta base, creamos nuestro primer diagrama de dispersión.
Ahora que ya dominas la estructura ggplot(data, aes) + geom(), es el momento de ampliar nuestro repertorio. En este post, nos centraremos en los tres tipos de gráficos más comunes y útiles en el análisis de datos. Son los verdaderos “caballos de batalla” que te permitirán responder a la gran mayoría de preguntas en tus proyectos:
Al final de este artículo, tendrás las herramientas para crear las visualizaciones fundamentales que forman la base de cualquier dashboard o informe.
Los gráficos de barras son perfectos para visualizar la relación entre una variable categórica (en el eje X) y un valor numérico (en el eje Y). En ggplot2, existen dos geometrías para crearlos, y entender su diferencia es clave.
geom_bar(): Contando las observacionesUsa geom_bar() cuando quieras que ggplot2 cuente por ti el número de veces que aparece cada categoría en tus datos. Solo necesitas mapear la variable categórica al eje X.
Pregunta: ¿Cuántos coches de cada tipo (class) hay en nuestro dataset mpg?
# Cargar la librería
library(tidyverse)
# Gráfico de barras usando geom_bar()
ggplot(data = mpg, mapping = aes(x = class)) +
geom_bar()
ggplot2 ha contado automáticamente cuántas filas corresponden a “compact”, “midsize”, “suv”, etc., y ha dibujado una barra con esa altura para cada una.
geom_col(): Cuando ya tienes el valorUsa geom_col() (de columna) cuando tu dataframe ya contiene una columna con el valor numérico que quieres representar. En este caso, debes mapear dos variables en aes(): la categoría al eje X y el valor al eje Y.
Pregunta: ¿Cuál es el consumo medio en autopista (hwy) para cada tipo de coche (class)?
Primero, necesitamos calcular esa media. Usaremos dplyr, otra herramienta del tidyverse.
# 1. Calcular la media de 'hwy' para cada 'class'
mpg_summary <- mpg %>%
group_by(class) %>%
summarise(
consumo_medio_hwy = mean(hwy)
)
# Vemos la tabla que hemos creado
print(mpg_summary)# A tibble: 7 × 2
class consumo_medio_hwy
<chr> <dbl>
1 2seater 24.8
2 compact 28.3
3 midsize 27.3
4 minivan 22.4
5 pickup 16.9
6 subcompact 28.1
7 suv 18.1# 2. Ahora usamos geom_col() para visualizarla
ggplot(data = mpg_summary, mapping = aes(x = class, y = consumo_medio_hwy)) +
geom_col()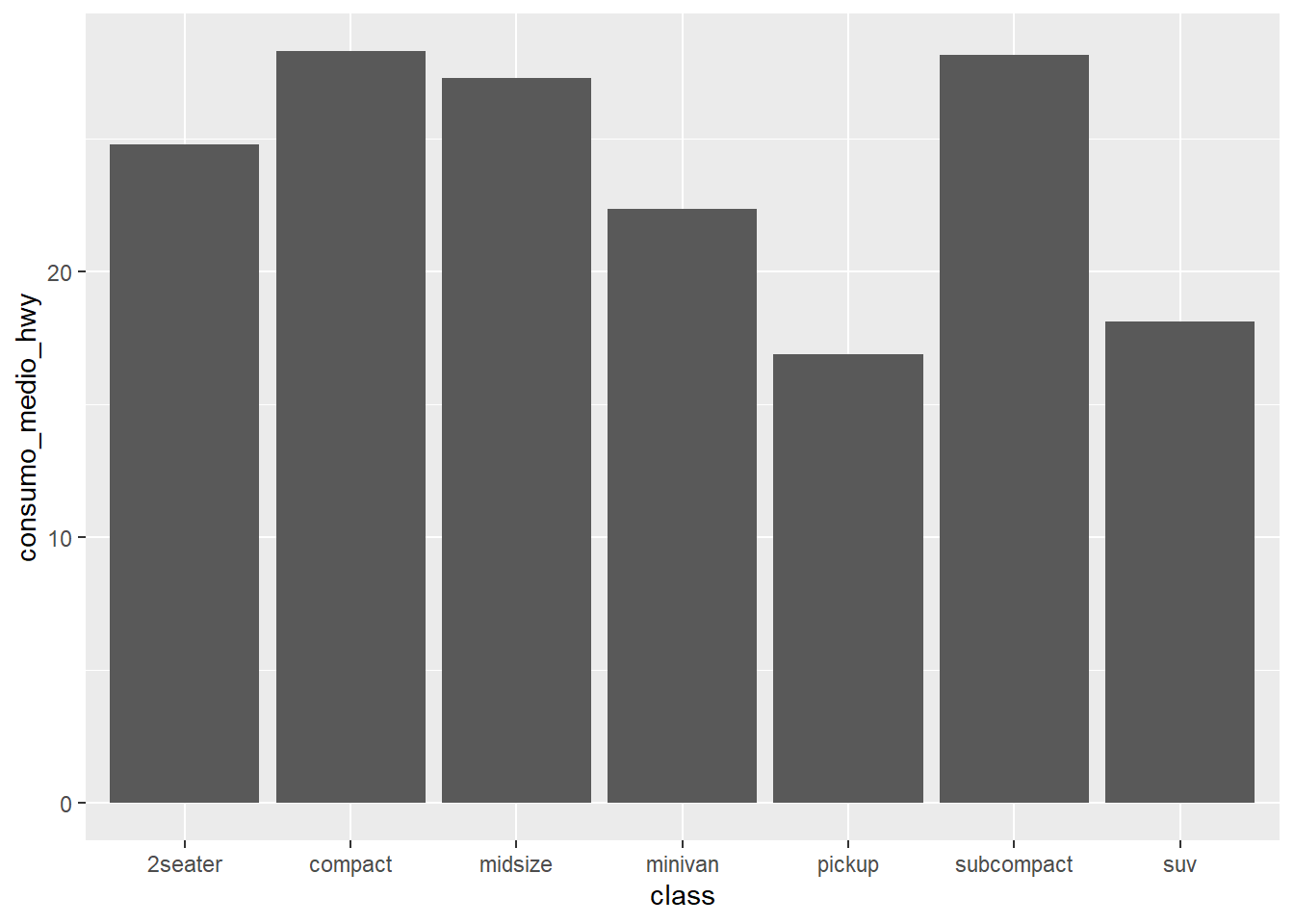
Aquí, no estamos contando coches. Le estamos diciendo a ggplot2 que dibuje una barra para cada class con una altura igual al valor que ya hemos calculado en la columna consumo_medio_hwy.
Los gráficos de líneas son la herramienta ideal para mostrar cómo cambia una variable numérica a lo largo de una variable continua, que muy a menudo es el tiempo.
Para este ejemplo, usaremos el dataset economics, que también viene incluido en ggplot2 y contiene datos económicos de EE. UU. a lo largo del tiempo.
Pregunta: ¿Cómo ha evolucionado el número de desempleados (unemploy) a lo largo de los años?
# Vistazo rápido al dataset economics
glimpse(economics)Rows: 574
Columns: 6
$ date <date> 1967-07-01, 1967-08-01, 1967-09-01, 1967-10-01, 1967-11-01, …
$ pce <dbl> 506.7, 509.8, 515.6, 512.2, 517.4, 525.1, 530.9, 533.6, 544.3…
$ pop <dbl> 198712, 198911, 199113, 199311, 199498, 199657, 199808, 19992…
$ psavert <dbl> 12.6, 12.6, 11.9, 12.9, 12.8, 11.8, 11.7, 12.3, 11.7, 12.3, 1…
$ uempmed <dbl> 4.5, 4.7, 4.6, 4.9, 4.7, 4.8, 5.1, 4.5, 4.1, 4.6, 4.4, 4.4, 4…
$ unemploy <dbl> 2944, 2945, 2958, 3143, 3066, 3018, 2878, 3001, 2877, 2709, 2…# Gráfico de líneas usando geom_line()
ggplot(data = economics, mapping = aes(x = date, y = unemploy)) +
geom_line()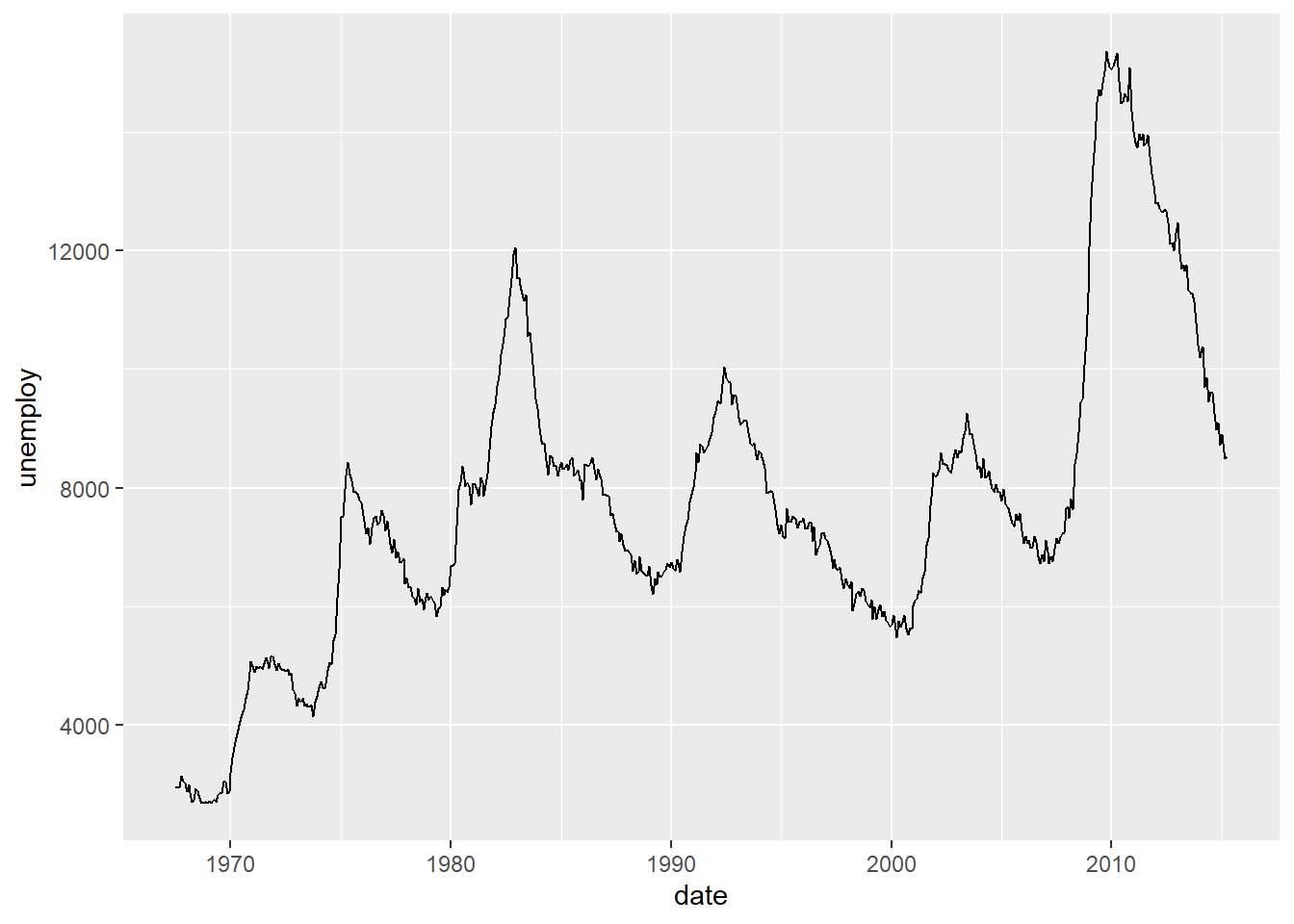
La lógica es la misma: mapeamos la fecha (date) al eje X y el número de desempleados (unemploy) al eje Y. Luego, añadimos la capa geom_line(), que conecta los puntos de datos consecutivos con una línea, revelando la tendencia a lo largo del tiempo.
Mientras que los gráficos de barras muestran variables categóricas, los histogramas son la herramienta para explorar la distribución de una única variable continua.
Un histograma divide el rango de valores de la variable en una serie de intervalos o “contenedores” (bins) y luego cuenta cuántas observaciones caen en cada uno.
Pregunta: ¿Cómo se distribuye el consumo en autopista (hwy) de todos los coches en el dataset mpg? ¿Hay muchos coches eficientes? ¿Son raros los coches que consumen mucho?
# Histograma básico con geom_histogram()
ggplot(data = mpg, mapping = aes(x = hwy)) +
geom_histogram()`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.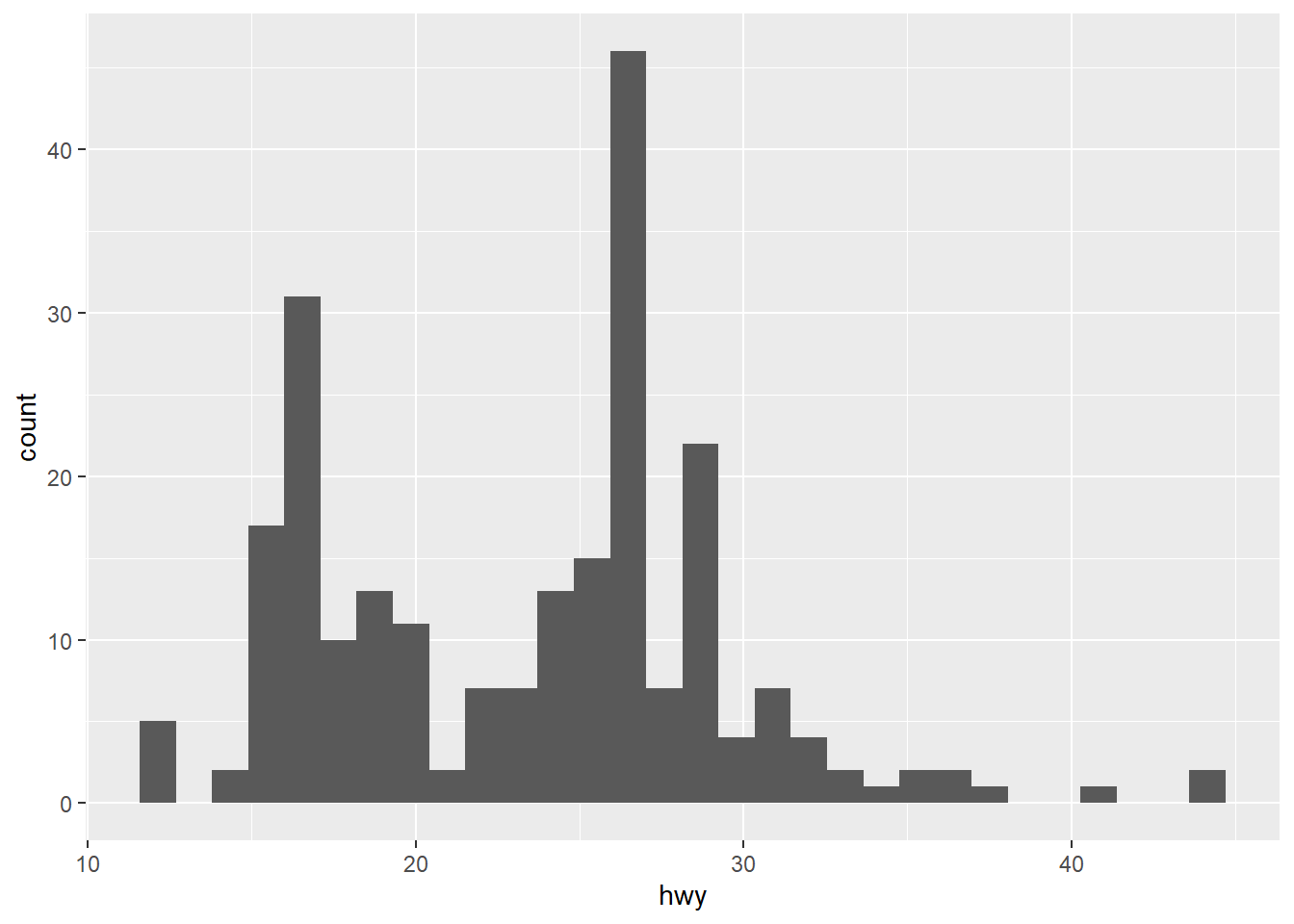
ggplot2 nos avisa de que está usando 30 bins por defecto. El gráfico nos muestra que la mayoría de los coches se agrupan en un consumo de entre 15 y 30 millas por galón, con una cola de coches mucho más eficientes que llegan hasta casi 45 mpg.
binsEl número de bins puede cambiar drásticamente la apariencia y la interpretación de un histograma. Podemos ajustarlo con el argumento bins o, de forma más precisa, con binwidth (anchura del contenedor).
Veamos la diferencia:
# Histograma con contenedores más anchos (menos detalle)
ggplot(data = mpg, mapping = aes(x = hwy)) +
geom_histogram(binwidth = 5)
# Histograma con contenedores más estrechos (más detalle)
ggplot(data = mpg, mapping = aes(x = hwy)) +
geom_histogram(binwidth = 1)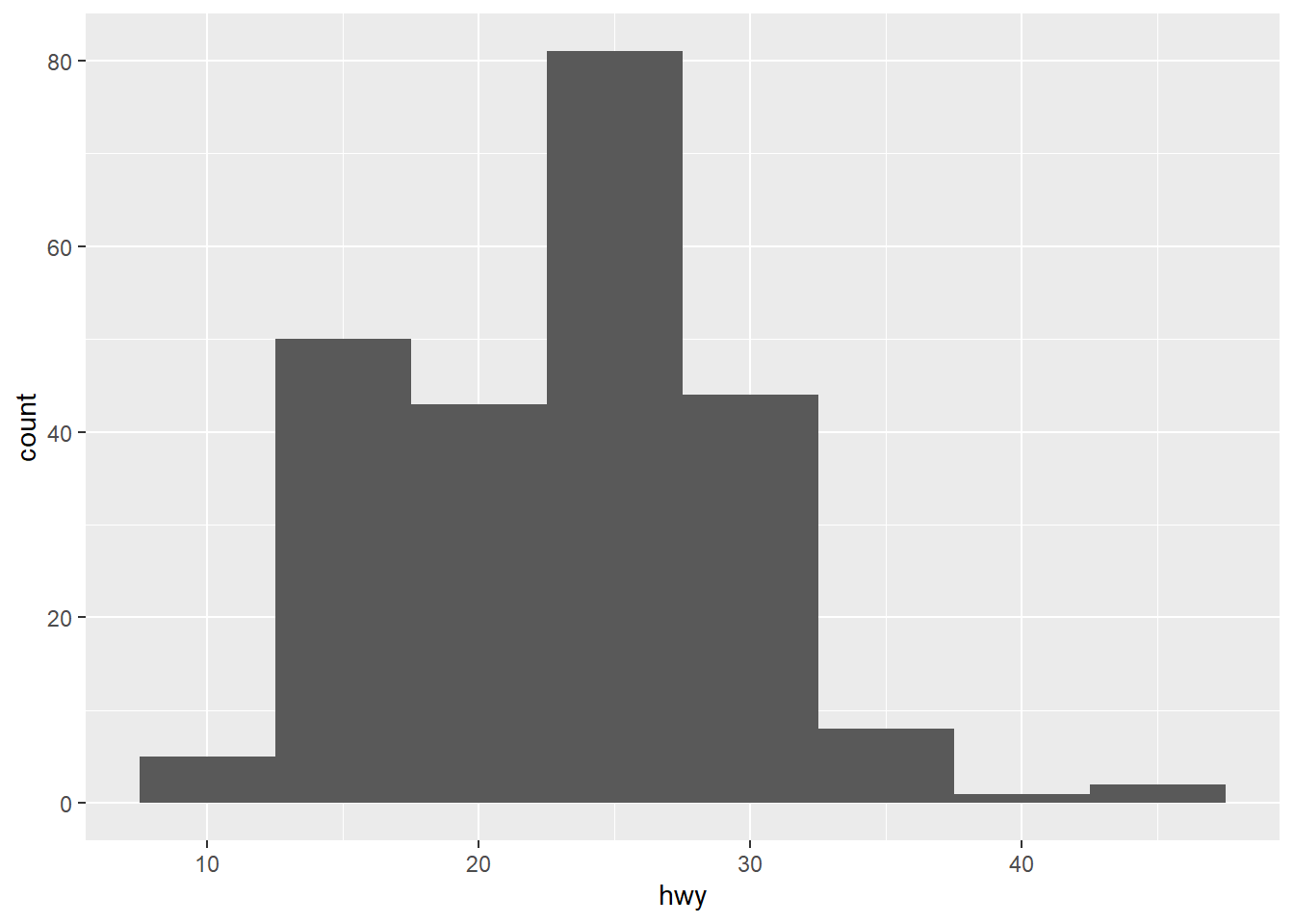
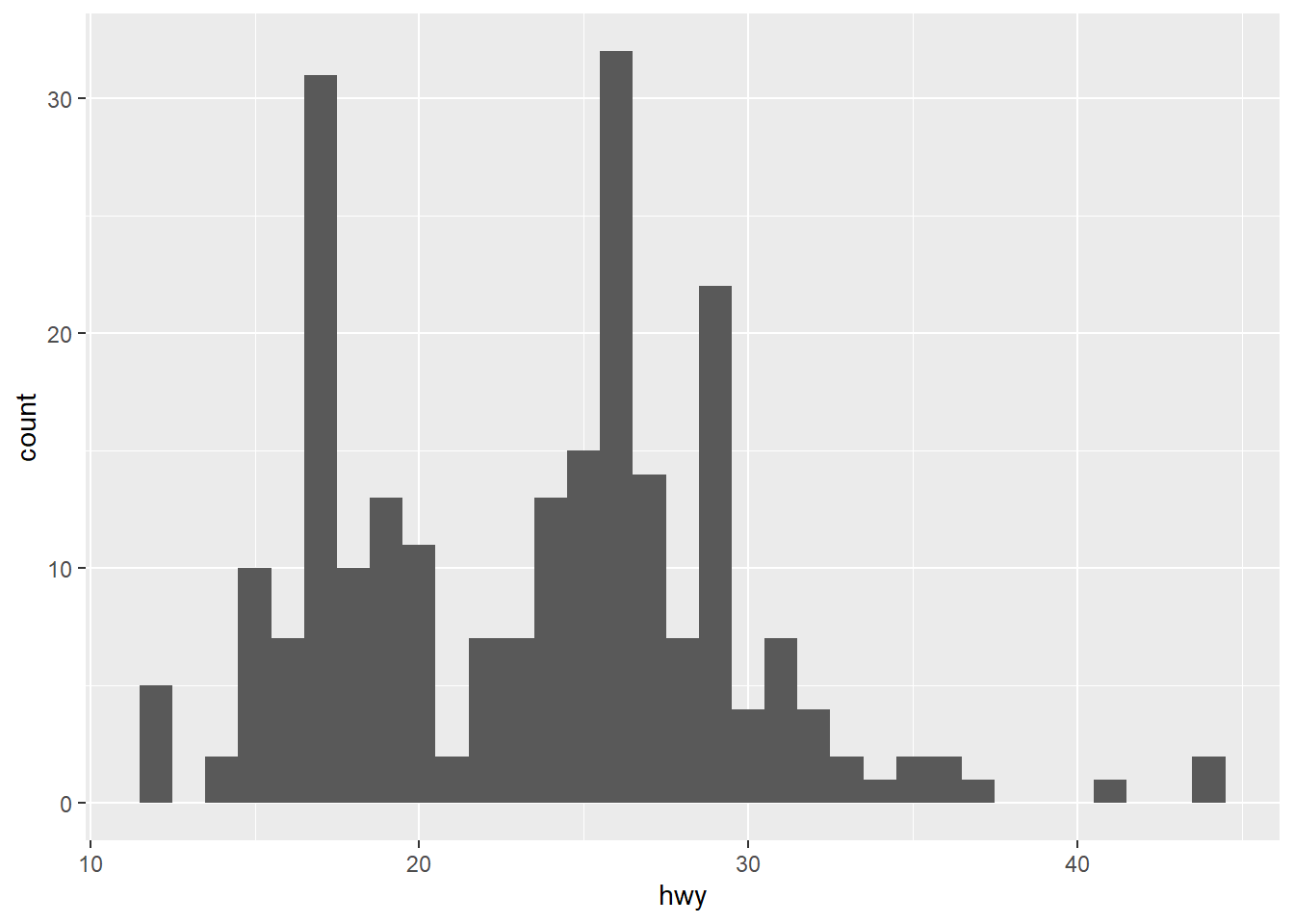
Como puedes ver, no hay un número “correcto” de bins. Es una elección que depende de lo que quieras explorar. Jugar con binwidth es una parte fundamental del análisis exploratorio de datos.
¡Felicidades! Ya dominas las tres geometrías más importantes para el análisis de datos del día a día. Has aprendido a:
geom_bar para contar categorías y geom_col para visualizar valores precalculados.geom_line.geom_histogram.Lo más importante es que has visto cómo la misma “gramática” (data, aes, geom) se aplica a todos ellos, cambiando solo la capa geom para crear visualizaciones completamente diferentes.
En el próximo post, daremos el siguiente paso: aprenderemos a dar vida a estos gráficos, añadiendo colores, títulos y etiquetas para que comuniquen sus historias de forma aún más clara y efectiva.
Este post es parte de la serie “Iniciación a ggplot2: Guía para crear visualizaciones en R”.