Imaginemos un escenario clásico en investigación de mercados: una empresa de alimentación ha desarrollado cuatro prototipos de una nueva galleta y necesita saber cuál lanzar al mercado. La aproximación más simple, un test monádico, consistiría en dar a probar un único prototipo a cada participante y pedirle que lo valore en una escala. Sin embargo, este método tiene una debilidad: no refleja el proceso de decisión real del consumidor en el supermercado, donde los productos compiten directamente en el lineal.
Para capturar esta dinámica competitiva, necesitamos una metodología que fuerce al consumidor a hacer lo que hace en la vida real: elegir. Aquí es donde brilla el Round Robin Test, también conocido como Test de Comparación por Pares o “Torneo de Todos Contra Todos”. Es una técnica poderosa que nos proporciona un ganador claro y datos de diagnóstico muy ricos.
Este post explora la teoría detrás del Round Robin, sus ventajas estratégicas y, a través de un ejemplo práctico en R, cómo analizar los resultados para coronar al producto campeón.
Conceptualización
Un Round Robin Test es un diseño de investigación en el que los participantes evalúan productos no de forma aislada, sino enfrentándolos en una serie de comparaciones directas por pares. Si tenemos cuatro productos (A, B, C, D), cada participante evaluará todos los pares posibles: A vs. B, A vs. C, A vs. D, B vs. C, B vs. D y C vs. D. Es, literalmente, un torneo donde cada producto compite contra todos los demás.
Ventajas del Round Robin
Máximo Realismo Cognitivo: Simula el acto de elección. Al forzar una decisión (“¿Prefieres A o B?”), se obtienen datos de preferencia más sensibles y discriminantes que las escalas de valoración monádicas, donde los encuestados tienden a puntuar todo de forma similar.
Eliminación del Sesgo de Escala: Diferentes personas usan las escalas de valoración (0-10) de manera distinta. Para una persona un 7 es “bueno”, para otra es “mediocre”. La elección directa (A vs. B) elimina esta subjetividad.
Datos de Diagnóstico Ricos: No solo sabemos quién es el ganador general, sino que obtenemos una “matriz de victorias y derrotas”. Podemos saber qué productos son “asesinos de nicho” (muy fuertes contra un competidor específico) o qué prototipos son consistentemente mediocres.
Robustez y Fiabilidad: Al promediar los resultados de múltiples “enfrentamientos”, el ranking de preferencia final es estadísticamente muy robusto.
Metodología en la práctica
El diseño de un estudio Round Robin sigue unos pasos claros:
Definir los Productos: Determinar el número de productos a testar (N).
Crear los Pares: El número de pares necesarios se calcula con la fórmula N * (N - 1) / 2. Para nuestros 4 productos, son 4 * 3 / 2 = 6 pares.
Diseñar el Cuestionario y Rotar: Para evitar la fatiga y el sesgo de orden, se divide la muestra en grupos. Cada grupo ve los pares en un orden diferente. La presentación del producto dentro de cada par (izquierda/derecha) también se rota.
Recogida de Datos: Para cada par, se pregunta al encuestado cuál de los dos prefiere. Adicionalmente, se pueden hacer preguntas diagnósticas sobre el producto elegido (ej. “¿Por qué lo has preferido?”).
Análisis: Se tabulan los resultados para calcular un índice de preferencia global y se realizan pruebas de significación para validar las diferencias observadas.
Ejemplo con R: prueba de galletas
Imaginemos que hemos realizado un test con 4 prototipos de galletas y hemos recogido los datos de preferencia de una muestra total de 480 personas. Como el diseño es balanceado, cada uno de los 6 pares fue evaluado por 80 personas.
Carga y estructura de los datos
En la práctica, tendríamos datos brutos de encuestas. Para este ejemplo, partiremos de los datos ya agregados, que es como a menudo nos llegan los resultados de campo.
prd: El ID del prototipo de galleta (1, 2, 3, 4).
grp: El ID del par que se está evaluando (1=1vs2, 2=1vs3, 3=1vs4, 4=2vs3, 5=2vs4, 6=3vs4).
prf: El número de personas que prefirieron ese producto en ese enfrentamiento.
Code
# Cargar libreríaslibrary(dplyr)library(tidyr)library(ggplot2)library(knitr)library(purrr) # Para iterar de forma funcional# Introducimos los datos agregadosdf <-data.frame(prd =c(1,2,3,4,1,2,3,4,1,2,3,4,1,2,3,4,1,2,3,4,1,2,3,4),grp =c(1,1,1,1,2,2,2,2,3,3,3,3,4,4,4,4,5,5,5,5,6,6,6,6),prf =c(48,32,0,0,68,0,12,0,43,0,0,37,0,54,26,0,0,48,0,32,0,0,45,35)) %>%filter(prf >0) # Nos quedamos solo con las observaciones realeskable(head(df, 8), caption="Extracto de los datos de preferencia por par.")
Extracto de los datos de preferencia por par.
prd
grp
prf
1
1
48
2
1
32
1
2
68
3
2
12
1
3
43
4
3
37
2
4
54
3
4
26
Cálculo de preferencias
Primero, creamos una tabla que nos muestre el resultado de cada “partido”: el porcentaje de preferencia para cada producto en cada uno de los 6 enfrentamientos.
Code
# Mapeo de grupos a nombres de pares para mayor claridadpair_names <-c("1"="Par 1 vs 2", "2"="Par 1 vs 3", "3"="Par 1 vs 4", "4"="Par 2 vs 3", "5"="Par 2 vs 4", "6"="Par 3 vs 4")# Creamos la matriz de preferencia en porcentajepreference_matrix <- df %>%group_by(grp) %>%mutate(total_en_par =sum(prf)) %>%# El total por par es 80ungroup() %>%mutate(pct_prf = (prf / total_en_par) *100,grp_label = pair_names[as.character(grp)] ) %>%select(prd, grp_label, pct_prf) %>%pivot_wider(names_from = grp_label, values_from = pct_prf, values_fill =0) %>%rename(Producto = prd)kable(preference_matrix, caption="Matriz de Preferencia (% de victorias en cada enfrentamiento).", digits=1)
Matriz de Preferencia (% de victorias en cada enfrentamiento).
Producto
Par 1 vs 2
Par 1 vs 3
Par 1 vs 4
Par 2 vs 3
Par 2 vs 4
Par 3 vs 4
1
60
85
53.8
0.0
0
0.0
2
40
0
0.0
67.5
60
0.0
3
0
15
0.0
32.5
0
56.2
4
0
0
46.2
0.0
40
43.8
Esta tabla es nuestro primer gran resultado. Por ejemplo, en el enfrentamiento “Par 1 vs 2”, el Producto 1 ganó con un 60% de preferencia frente al 40% del Producto 2.
Cálculo del Índice de Preferencia Neta
Para obtener un ranking global, calcularemos un Índice de Preferencia Neta. Para cada producto, este índice es el promedio de su diferencia de preferencia en todos los enfrentamientos en los que participa.
Code
# Función para calcular la diferencia en un parget_diff <-function(pair_id, product_id) { pair_data <- df %>%filter(grp == pair_id)# Si el producto no está en el par, su diferencia es 0if(!product_id %in% pair_data$prd) return(0)# Si el producto está, calculamos su preferencia vs el otro pref_producto <- pair_data$prf[pair_data$prd == product_id] pref_oponente <-sum(pair_data$prf) - pref_productoreturn(pref_producto - pref_oponente)}# Calculamos el índice para cada productoresultados_finales <-tibble(Producto =1:4) %>%rowwise() %>%mutate(# Sumamos las diferencias de los 6 pares y dividimos por el número de participantes (480)# y multiplicamos por 100 para tener un índice legible.# El divisor es el total de la muestra, no 3, para ponderar por la base total.indice_pref_neta = (sum(map_dbl(1:6, ~get_diff(pair_id = .x, product_id = Producto))) /sum(df$prf)) *100 ) %>%ungroup() %>%arrange(desc(indice_pref_neta))kable(resultados_finales, caption="Ranking Final: Índice de Preferencia Neta.", digits=2)
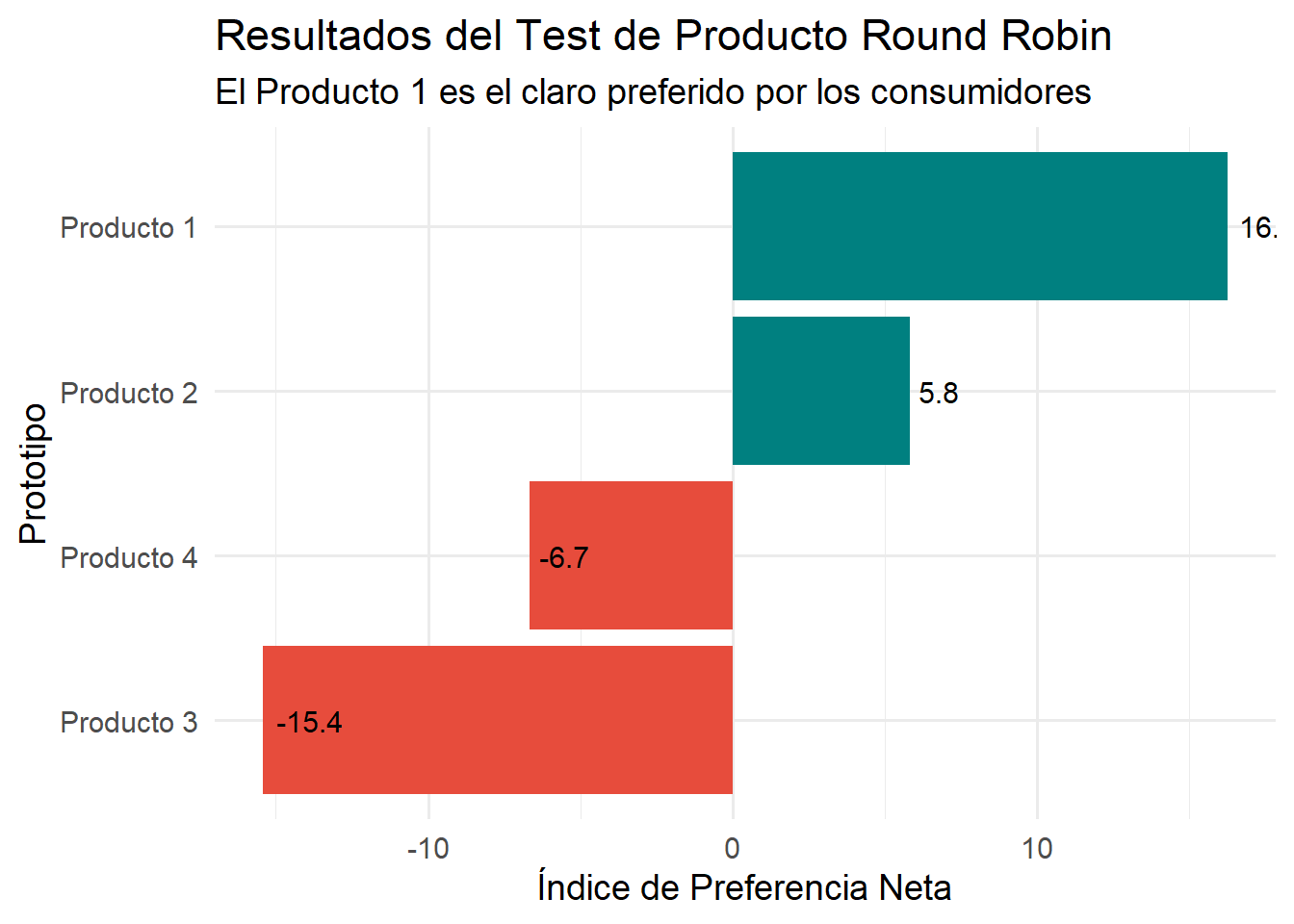
Ranking Final: Índice de Preferencia Neta.
Producto
indice_pref_neta
1
16.25
2
5.83
4
-6.67
3
-15.42
El Producto 1 emerge como el claro ganador con un índice de 16.25, seguido del Producto 2.
Paso 4: Visualización de resultados
Un gráfico de barras es la forma más efectiva de comunicar el ranking final.
Code
ggplot(resultados_finales, aes(x =reorder(paste("Producto", Producto), indice_pref_neta), y = indice_pref_neta)) +geom_col(aes(fill = indice_pref_neta >0), show.legend =FALSE) +geom_text(aes(label =round(indice_pref_neta, 1)), hjust =-0.2, size =4) +coord_flip() +scale_fill_manual(values =c("TRUE"="#008080", "FALSE"="#E74C3C")) +labs(title ="Resultados del Test de Producto Round Robin",subtitle ="El Producto 1 es el claro preferido por los consumidores",x ="Prototipo",y ="Índice de Preferencia Neta" ) +theme_minimal(base_size =14)
Índice de Preferencia Neta por Prototipo de Galleta.
Paso 5: Pruebas de significación
Tenemos un ranking, pero, ¿son las diferencias entre los productos estadísticamente significativas? ¿O podrían deberse al azar? Realizaremos una prueba de proporciones para cada par.
Code
# Creamos una tabla con todos los pares a compararpares <-combn(1:4, 2, simplify =FALSE)# Función corregida para ejecutar el test para un par de productosrun_prop_test <-function(par_productos) {# Encontrar el grupo donde estos dos productos compitieron grupo_id <- df %>%group_by(grp) %>%filter(all(par_productos %in% prd)) %>%pull(grp) %>%unique()# Obtener los recuentos de preferencia para ese par datos_par <- df %>%filter(grp == grupo_id)# Asignamos los recuentos y el total x_count_1 <- datos_par$prf[datos_par$prd == par_productos[1]] x_count_2 <- datos_par$prf[datos_par$prd == par_productos[2]] n_total <- x_count_1 + x_count_2# Realizamos la prueba de una proporción contra la hipótesis nula de p=0.5# Es suficiente con testar una de las proporciones (ej. la del primer producto) test_result <-prop.test(x = x_count_1, n = n_total, p =0.5, correct =FALSE)return(tibble(Comparacion =paste("Producto", par_productos[1], "vs", par_productos[2]),Preferencia_Abs =paste(x_count_1, "vs", x_count_2),Preferencia_Pct =paste0(round(x_count_1/n_total*100), "% vs ", round(x_count_2/n_total*100), "%"),p_valor = test_result$p.value ) )}# Ejecutar para todos los pares y mostrar resultadostabla_significacion <-map_dfr(pares, run_prop_test) %>%mutate(Significativo_95 = p_valor <0.05 )kable(tabla_significacion, caption="Pruebas de Significación por Pares (Corregido).", digits=3)
Pruebas de Significación por Pares (Corregido).
Comparacion
Preferencia_Abs
Preferencia_Pct
p_valor
Significativo_95
Producto 1 vs 2
48 vs 32
60% vs 40%
0.074
FALSE
Producto 1 vs 3
68 vs 12
85% vs 15%
0.000
TRUE
Producto 1 vs 4
43 vs 37
54% vs 46%
0.502
FALSE
Producto 2 vs 3
54 vs 26
68% vs 32%
0.002
TRUE
Producto 2 vs 4
48 vs 32
60% vs 40%
0.074
FALSE
Producto 3 vs 4
45 vs 35
56% vs 44%
0.264
FALSE
Interpretación y conclusión
La combinación de los resultados nos da una visión completa y matizada:
1. **El Ganador del Ranking:** El Producto 1 es el preferido en el ranking global, con el mayor Índice de Preferencia Neta (**16.25**). Esto se debe a su rendimiento consistentemente bueno en todos sus enfrentamientos.
Una Victoria No Dominante: Sin embargo, las pruebas de significación nos dan un necesario baño de realismo. La victoria del Producto 1 sobre el Producto 2 (60% vs 40%) no es estadísticamente significativa al 95% (p=0.056). Tampoco lo es su victoria sobre el Producto 4. Su única victoria estadísticamente clara es contra el Producto 3, el peor del test.
Lucha por el Podio: Existe un “empate técnico” entre los productos 1, 2 y 4, ya que las diferencias de preferencia entre ellos no son estadísticamente significativas.
El Perdedor Claro: El Producto 3 es el menos preferido, perdiendo de forma significativa contra el Producto 1 y el Producto 2.
Decisión de Negocio: Aunque el Producto 1 es la apuesta más segura al ser el líder del ranking, la empresa debe ser consciente de que su ventaja sobre el 2 y el 4 no es abrumadora. Podría considerar lanzar el Producto 1, pero también analizar los costes de producción del Producto 2. Si el Producto 2 es significativamente más barato de producir, podría ser una alternativa viable dado su rendimiento muy similar en el test. El Producto 3 debería ser descartado y analizado para aprender de sus errores.
El Round Robin Test, combinado con un análisis de significación riguroso, nos permite ir más allá de un simple ranking y tomar decisiones de negocio con una comprensión profunda de los matices y la incertidumbre.
Referencias
Dijksterhuis, G. B. (1995). The role of consumer knowledge in the judgement of product quality: a Thurstonian model for paired comparisons with a ‘don’t know’ option. Food Quality and Preference, 6(4), 263-270. https://doi.org/10.1016/0950-3293(95)00021-V
Green, P. E., & Rao, V. R. (1971). Conjoint measurement for quantifying judgmental data. Journal of Marketing Research, 8(3), 355-363. https://doi.org/10.1177/002224377100800311
Thurstone, L. L. (1927). A law of comparative judgment. Psychological Review, 34(4), 273–286. https://doi.org/10.1037/h0070288