Code
library(tidyverse)En los posts anteriores, hemos aprendido a construir visualizaciones robustas y a darles vida con colores, etiquetas y títulos. Hemos visto cómo mapear una tercera variable al color o la forma puede enriquecer un gráfico. Pero, ¿qué sucede cuando un gráfico se satura? ¿Cuándo hay tantos puntos o categorías que, incluso con colores, el resultado es un caos difícil de interpretar?
A veces, para contar una historia más clara, no necesitas añadir más a un solo gráfico; necesitas dividirlo en partes más pequeñas y manejables. Aquí es donde entra en juego una de las funcionalidades más elegantes y potentes de ggplot2: las facetas (facets).
El faceteado es el arte de “dividir y vencerás”. Te permite tomar un gráfico y dividirlo en múltiples subgráficos (un panel o matriz de gráficos), basándote en las categorías de una o más variables. Cada subgráfico muestra el mismo tipo de visualización pero para un subconjunto diferente de los datos.
En este post, exploraremos las dos funciones principales de faceteado, facet_wrap() y facet_grid(), y veremos cómo nos permiten desenredar historias complejas y presentar comparaciones de una manera increíblemente clara y efectiva.
facet_wrap(): La herramienta flexible para una variableImagina que tienes una baraja de cartas y quieres ordenarla por palos. Una forma de hacerlo sería crear cuatro montones, uno para los corazones, otro para los diamantes, y así sucesivamente. facet_wrap() hace exactamente eso con tus datos.
Usa facet_wrap() cuando quieras dividir tu visualización basándote en una única variable categórica. ggplot2 creará un subgráfico para cada nivel de esa variable y los organizará en una cuadrícula lo más cuadrada posible.
Retomemos nuestro diagrama de dispersión del post anterior, que muestra la relación entre cilindrada (displ) y consumo (hwy).
library(tidyverse)ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point()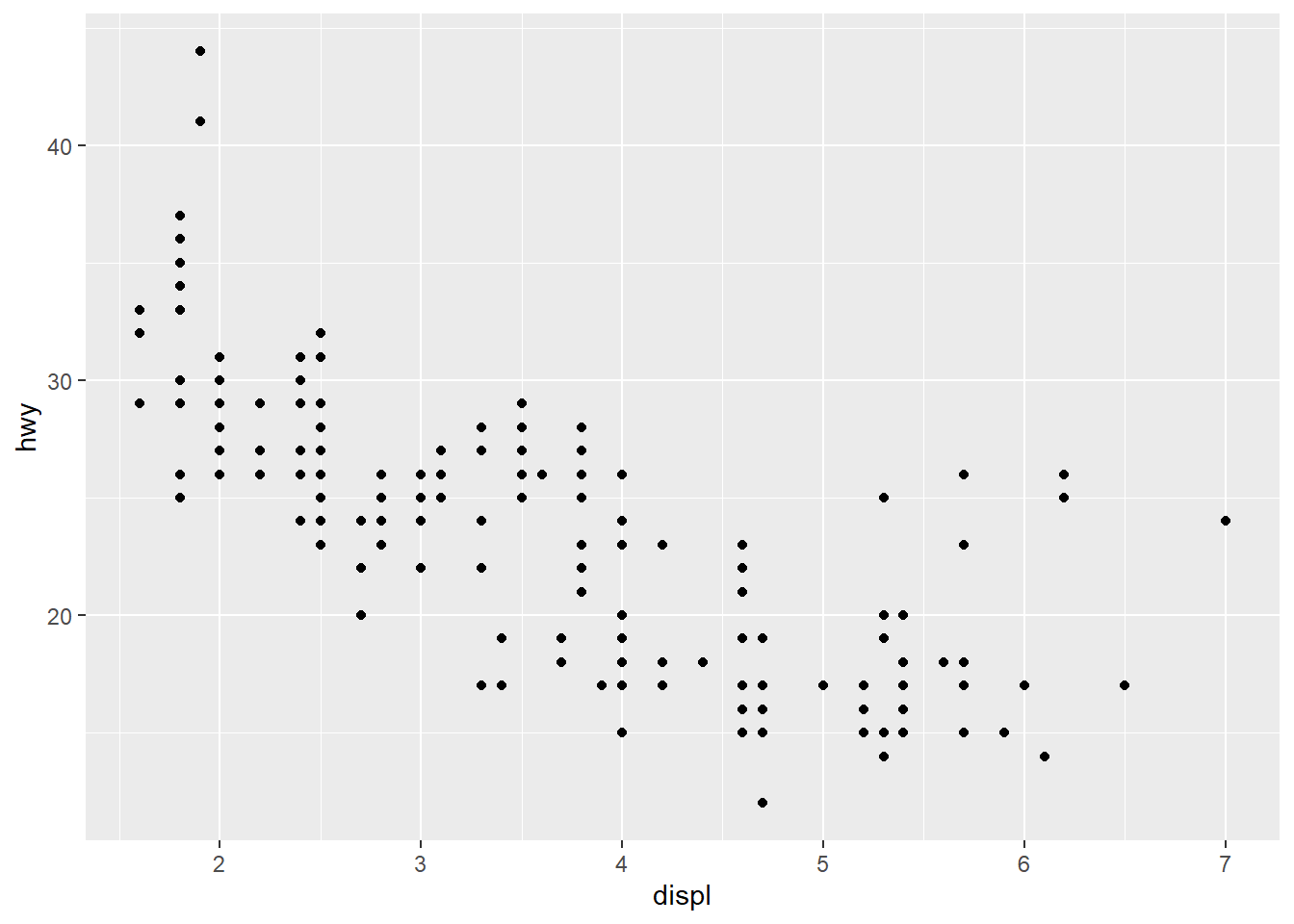
Ahora, queremos entender esta relación para cada class de coche. Podríamos usar el color, como hicimos antes, pero si quisiéramos analizar la tendencia de cada clase por separado, todos los puntos juntos pueden estorbar.
facet_wrap()Vamos a usar facet_wrap() para crear un diagrama de dispersión para cada class. La sintaxis es simple: se añade al final del código ggplot y se especifica la variable de faceteado precedida de una tilde (~).
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point() +
facet_wrap(~ class)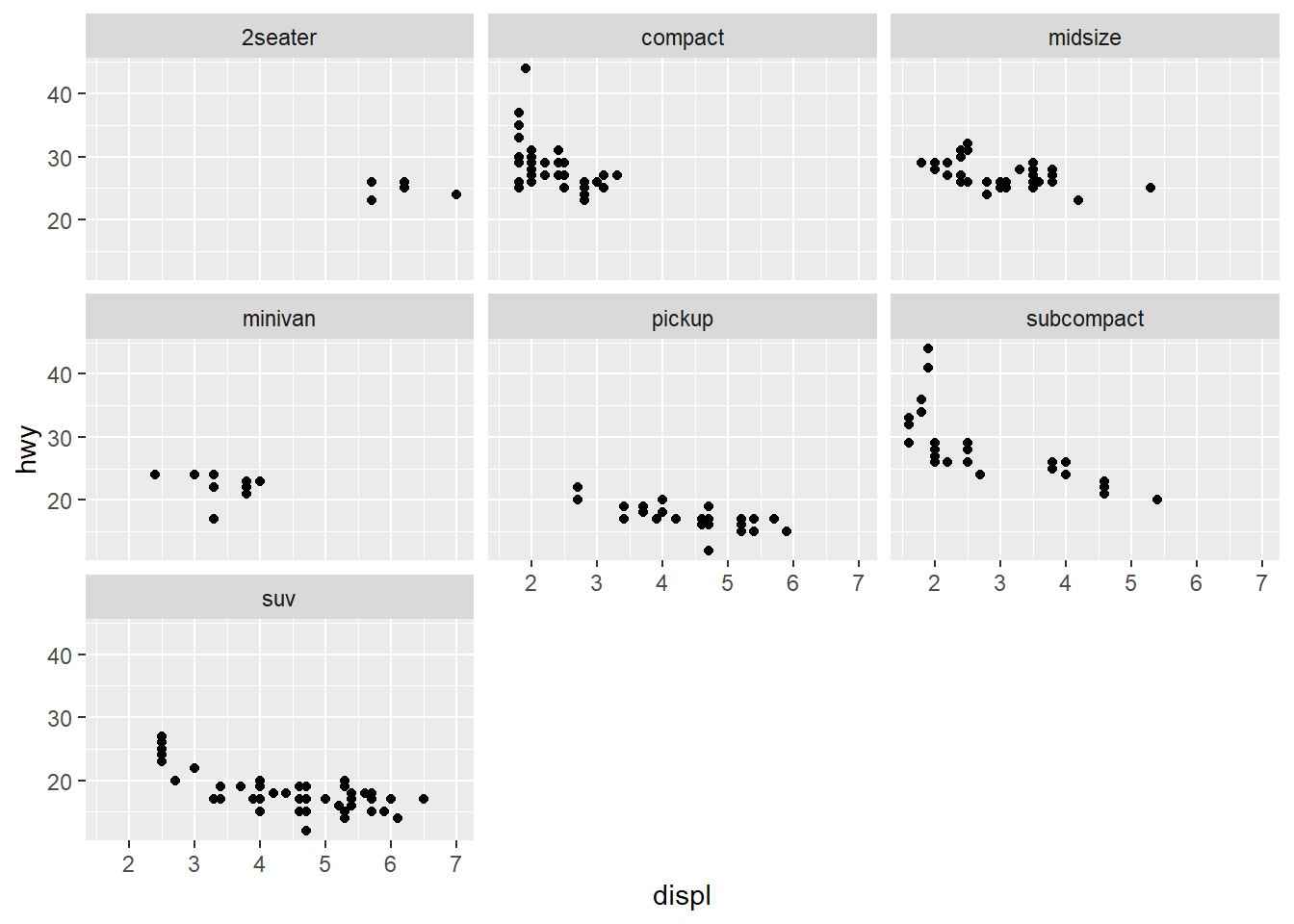
Con una sola línea de código, hemos creado siete gráficos distintos, uno para cada clase de coche. Ahora es mucho más fácil analizar y comparar:
2seater tiene motores grandes pero una eficiencia decente, mientras que los suv cubren un rango muy amplio de cilindradas con un consumo generalmente pobre.Por defecto, facet_wrap() intenta crear una cuadrícula cuadrada. Pero puedes controlar el número de filas o columnas con los argumentos nrow o ncol. Por ejemplo, para poner todos los gráficos en dos filas:
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point() +
facet_wrap(~ class, nrow = 2)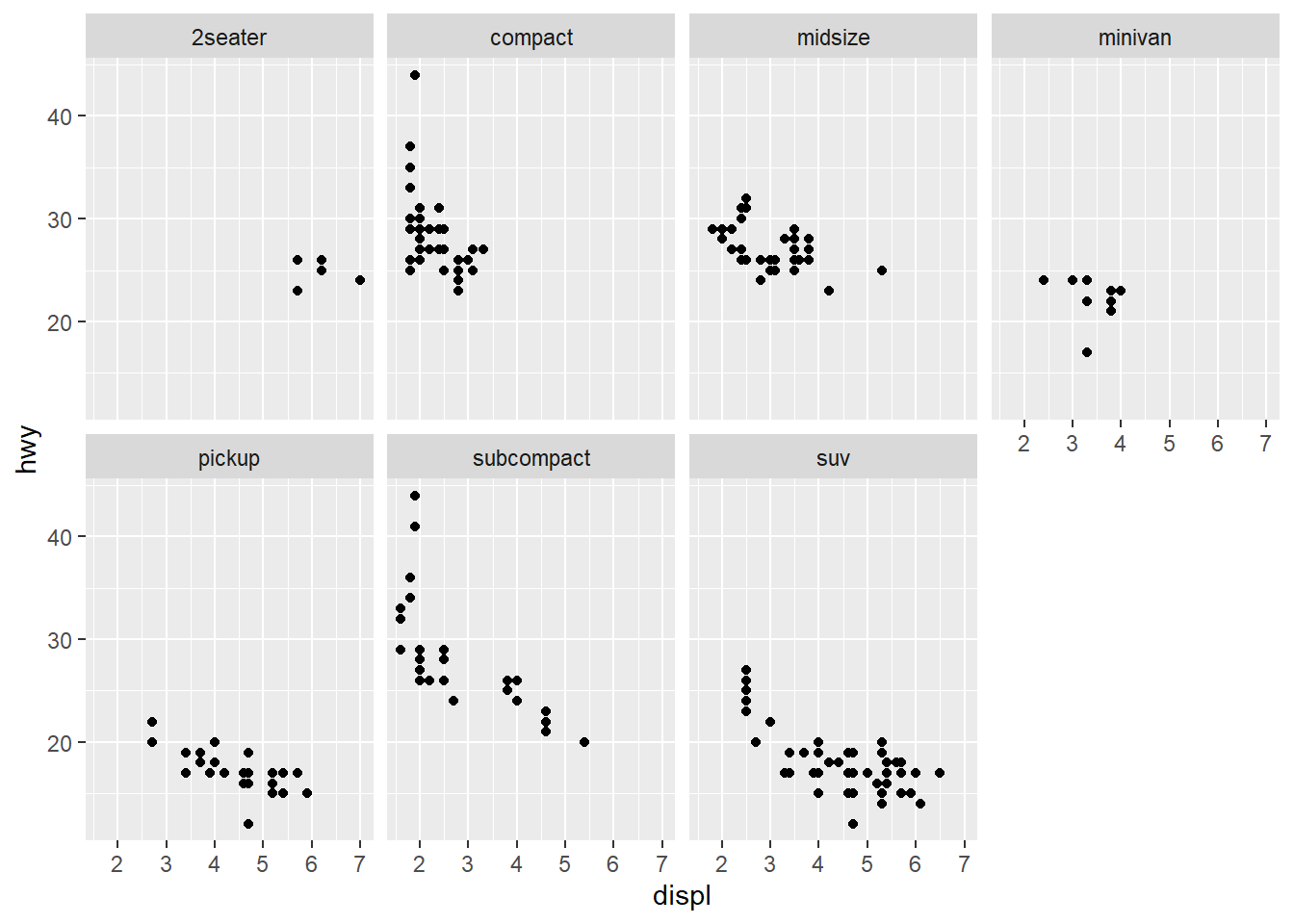
facet_grid(): La matriz estructurada para dos variablesSi facet_wrap() es como hacer montones con una baraja, facet_grid() es como organizar esas cartas en una tabla de doble entrada, como un tablero de ajedrez.
Usa facet_grid() cuando quieras dividir tu visualización basándote en las combinaciones de dos variables categóricas. Creará una matriz donde los niveles de una variable definen las filas y los niveles de la otra definen las columnas.
Pregunta de investigación: ¿Cómo cambia la relación entre cilindrada (displ) y consumo (hwy) dependiendo no solo del tipo de tracción (drv), sino también del número de cilindros (cyl)?
Esta pregunta implica tres variables continuas (displ, hwy) y dos categóricas (drv, cyl). Un solo gráfico sería un caos. Es el escenario perfecto para facet_grid().
La sintaxis es facet_grid(variable_filas ~ variable_columnas).
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point() +
facet_grid(drv ~ cyl)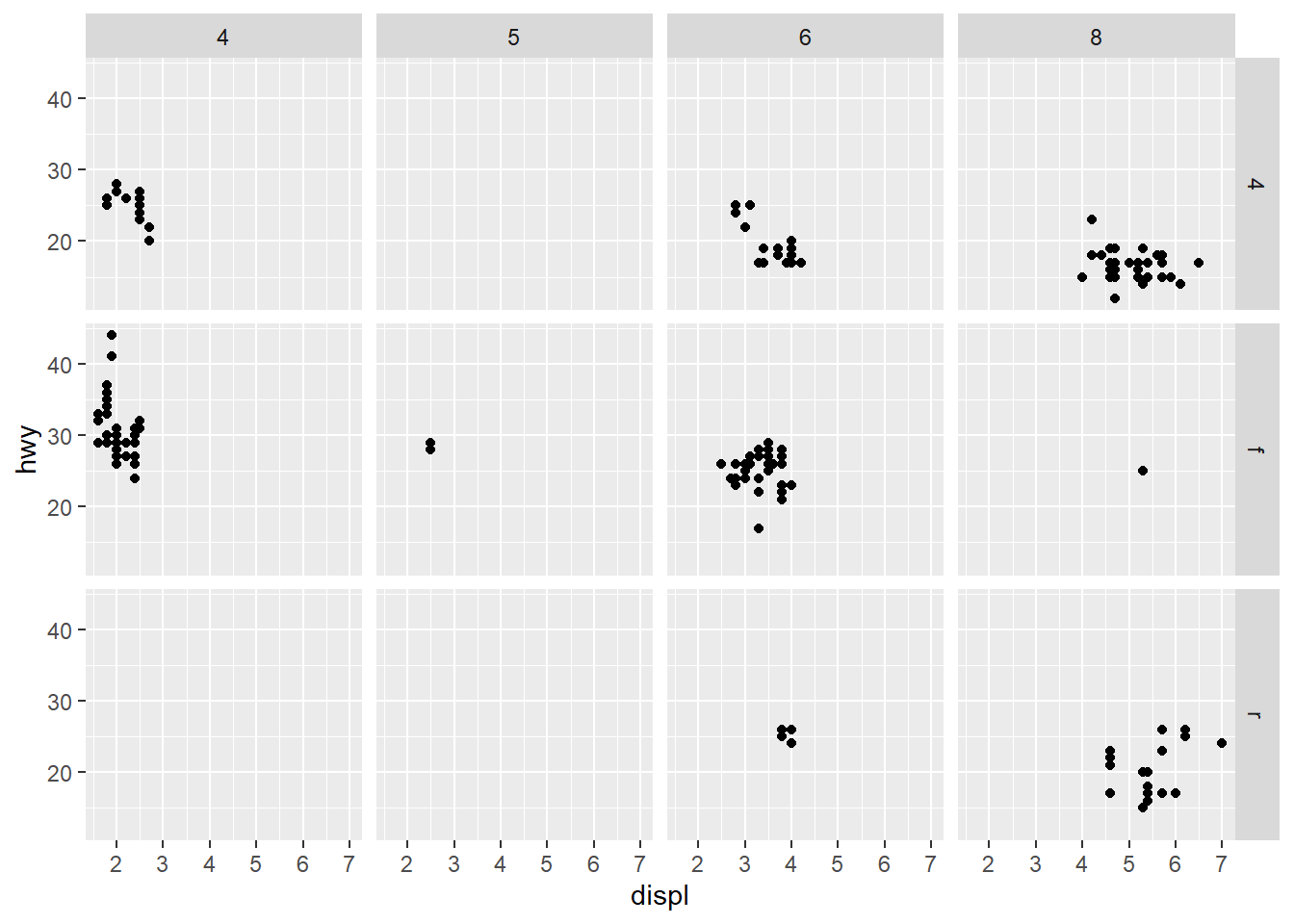
Este es un gráfico increíblemente denso en información, pero muy fácil de leer:
f (tracción delantera), vemos que solo existen coches de 4 y 6 cilindros.8 cilindros, vemos que solo existen coches de tracción trasera (r) y 4x4 (4), y que los de tracción trasera son, en general, más eficientes.facet_wrap vs. facet_grid?Aquí tienes una guía rápida para decidir cuál usar:
facet_wrap(~ A) si:
facet_grid(A ~ B) si:
Pro-Tip: También puedes usar facet_grid() con una sola variable usando un punto (.) como marcador de posición. facet_grid(. ~ A) creará una sola fila de gráficos, mientras que facet_grid(A ~ .) creará una sola columna.
Hoy has añadido a tu knowledge una de las herramientas más potentes de ggplot2. El faceteado te permite pasar de visualizaciones saturadas a paneles de gráficos claros y comparativos. Has aprendido a:
facet_wrap() para analizar una variable categórica.facet_grid() para explorar la interacción entre dos variables categóricas.Ahora que dominas los componentes básicos, las estéticas, las geometrías y las facetas, estás listo para el gran final. En nuestro próximo y último post de la serie, uniremos todo lo que hemos aprendido. Cogeremos un nuevo conjunto de datos y construiremos una visualización final, compleja y pulida desde el principio hasta el final, como un verdadero profesional de la visualización de datos.
Este post es parte de la serie “Iniciación a ggplot2: Guía para crear visualizaciones en R”.