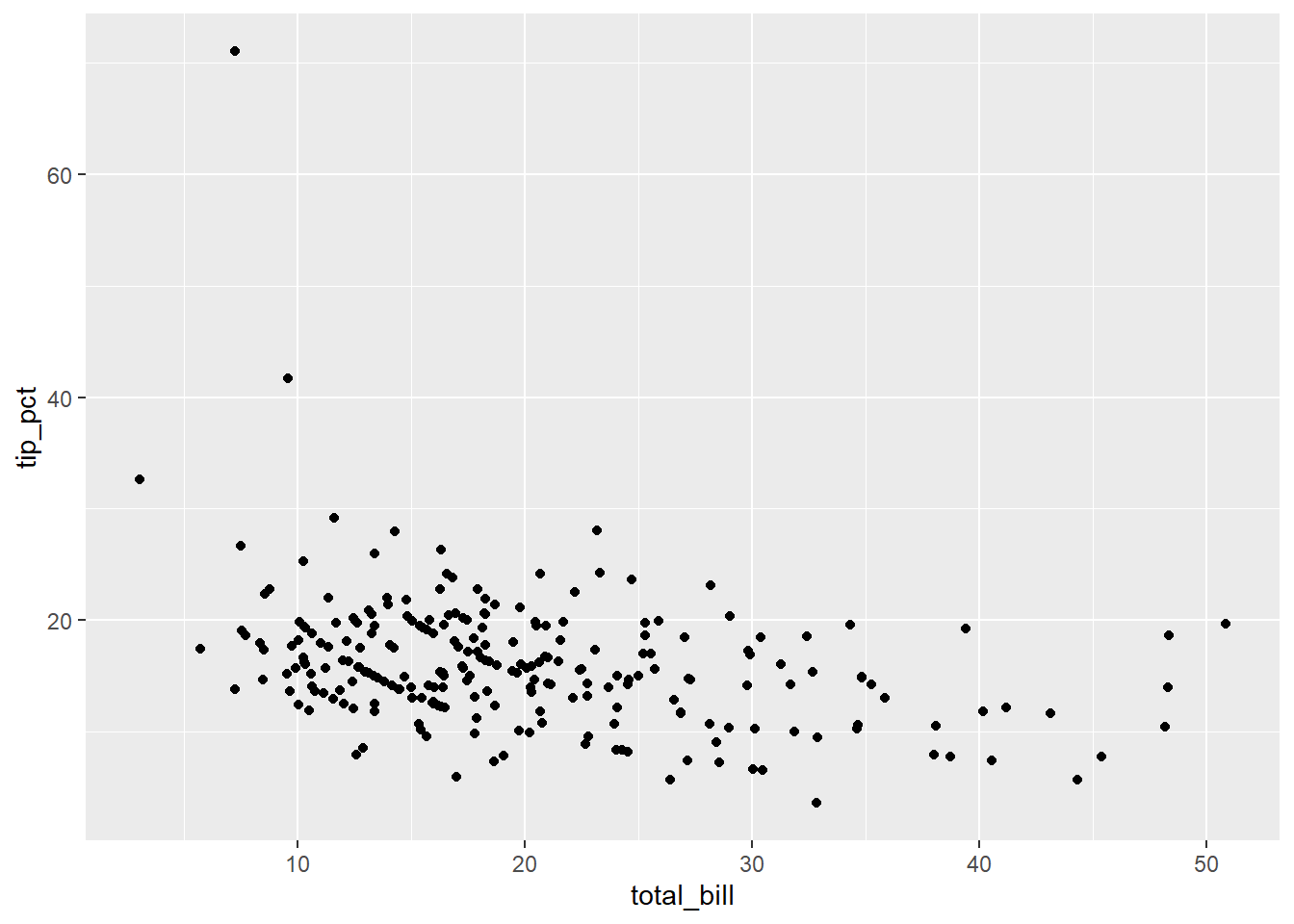
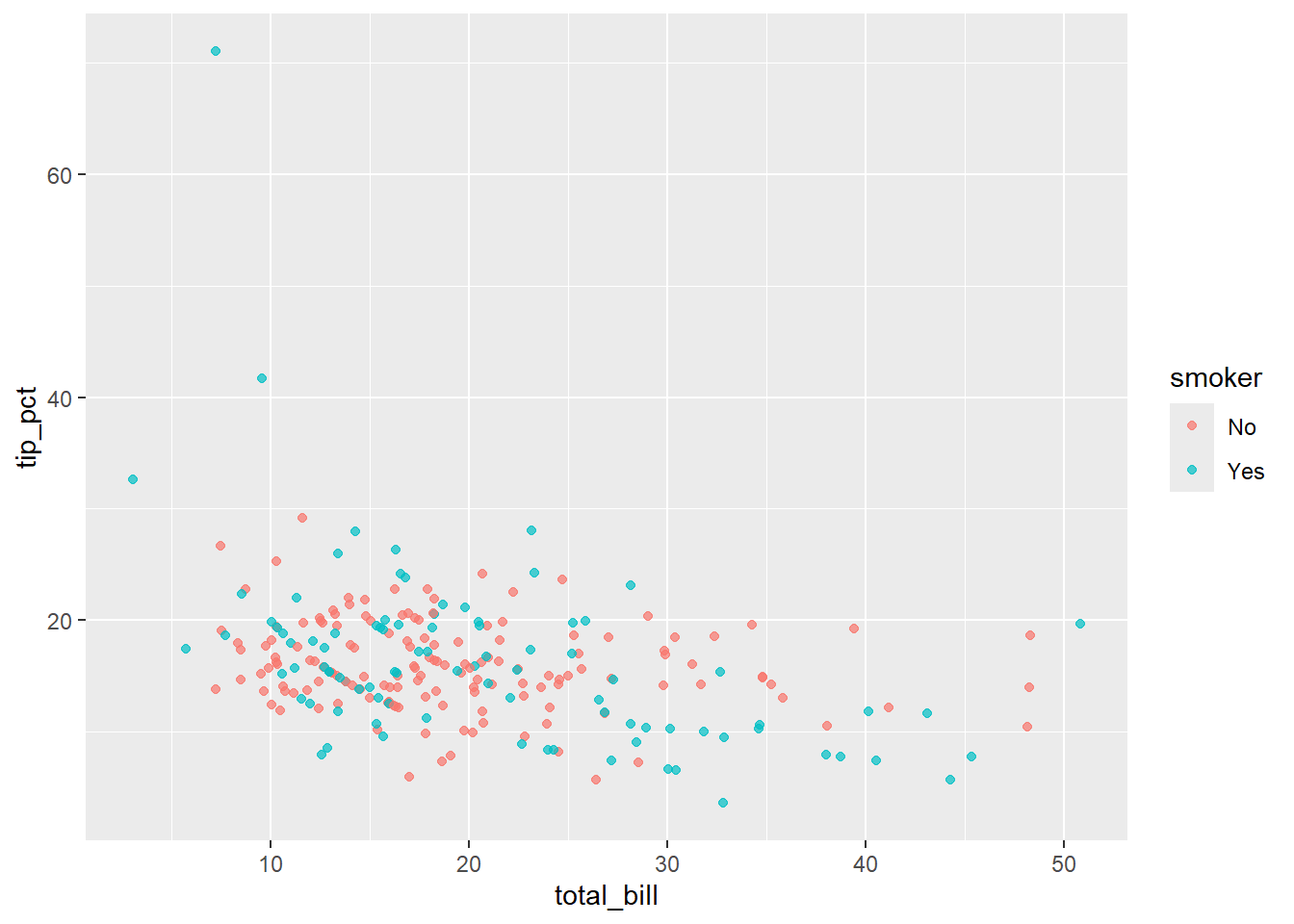
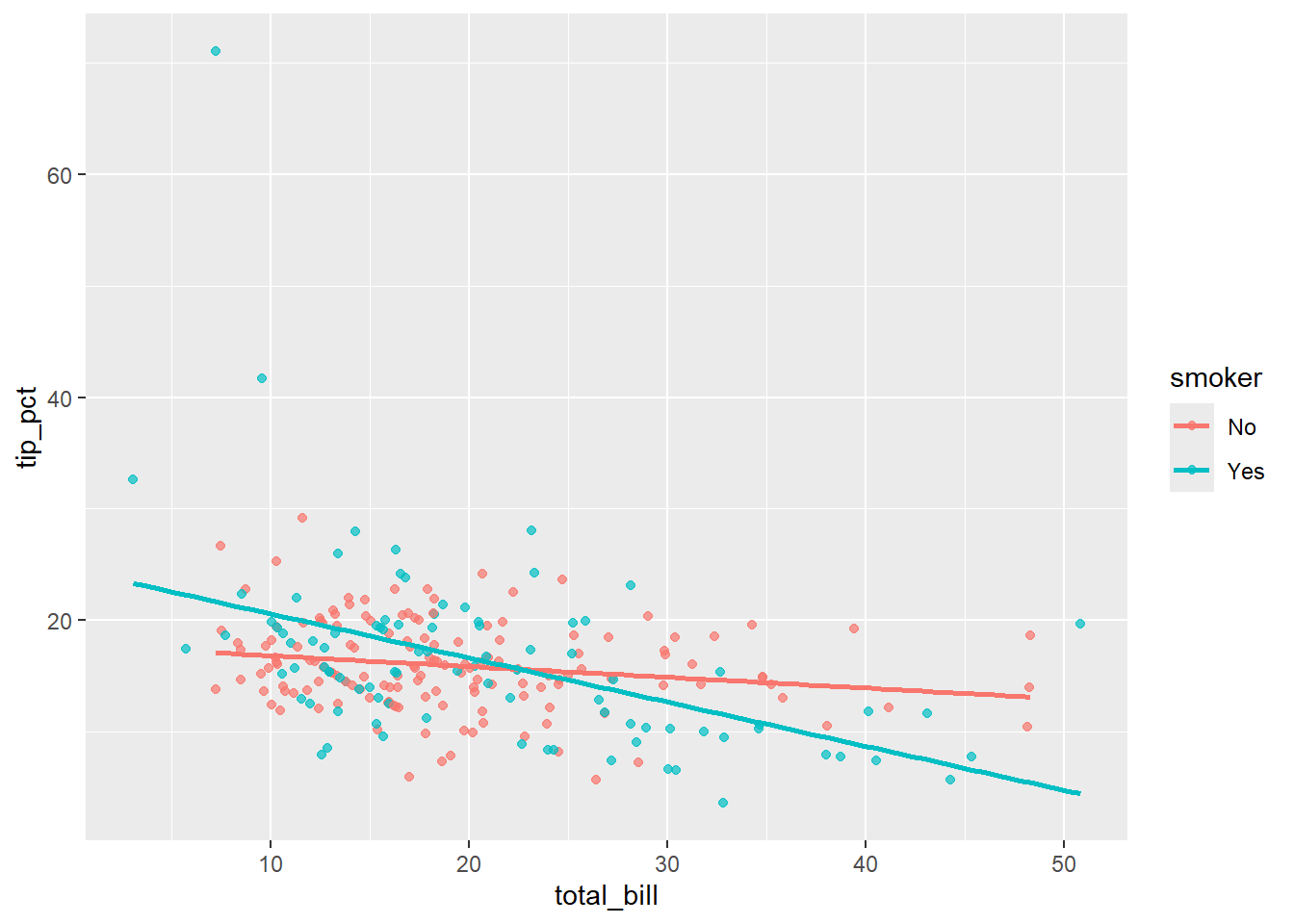
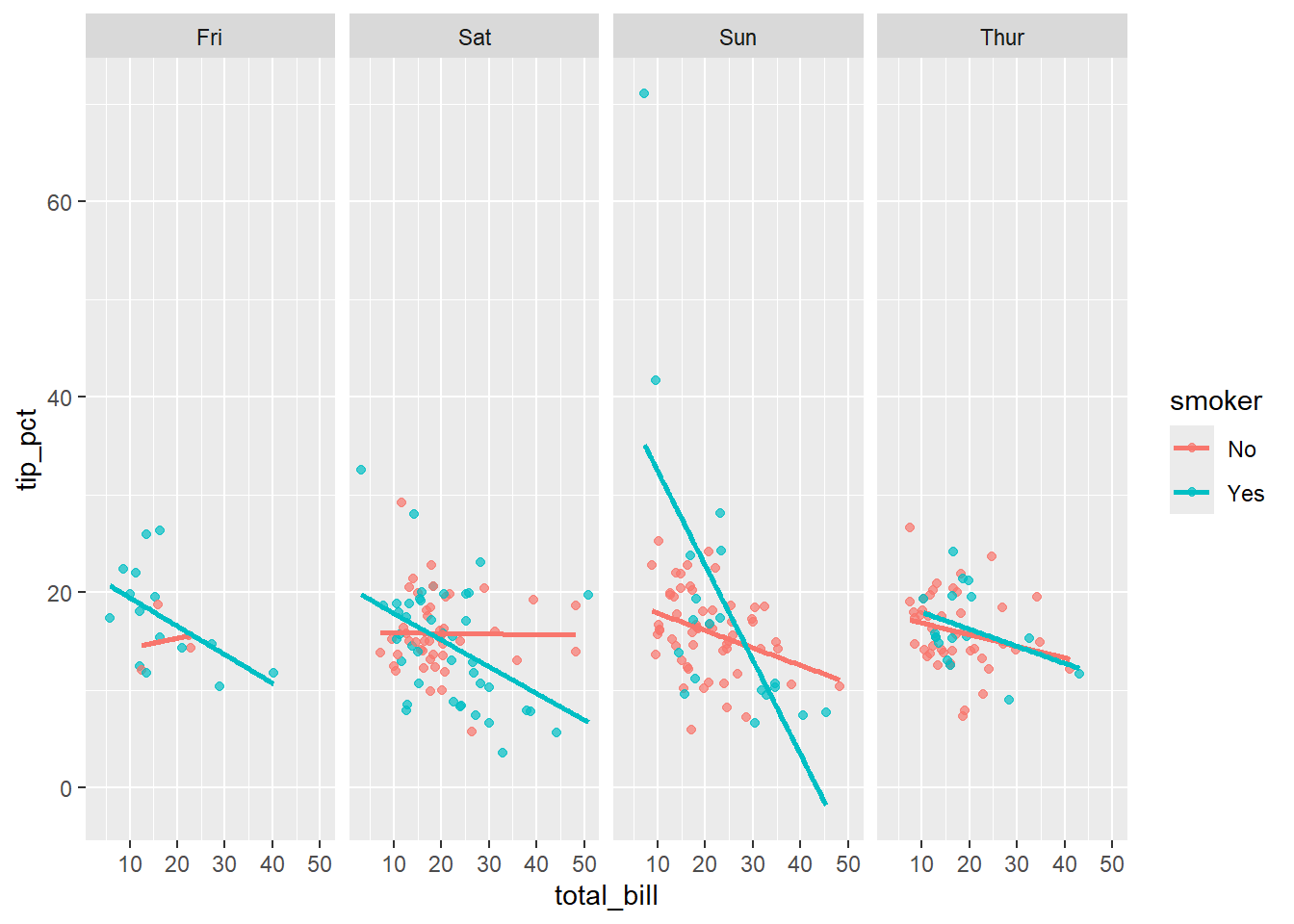
Rows: 244
Columns: 7
$ total_bill <dbl> 16.99, 10.34, 21.01, 23.68, 24.59, 25.29, 8.77, 26.88, 15.0…
$ tip <dbl> 1.01, 1.66, 3.50, 3.31, 3.61, 4.71, 2.00, 3.12, 1.96, 3.23,…
$ sex <fct> Female, Male, Male, Male, Female, Male, Male, Male, Male, M…
$ smoker <fct> No, No, No, No, No, No, No, No, No, No, No, No, No, No, No,…
$ day <fct> Sun, Sun, Sun, Sun, Sun, Sun, Sun, Sun, Sun, Sun, Sun, Sun,…
$ time <fct> Dinner, Dinner, Dinner, Dinner, Dinner, Dinner, Dinner, Din…
$ size <int> 2, 3, 3, 2, 4, 4, 2, 4, 2, 2, 2, 4, 2, 4, 2, 2, 3, 3, 3, 3,…